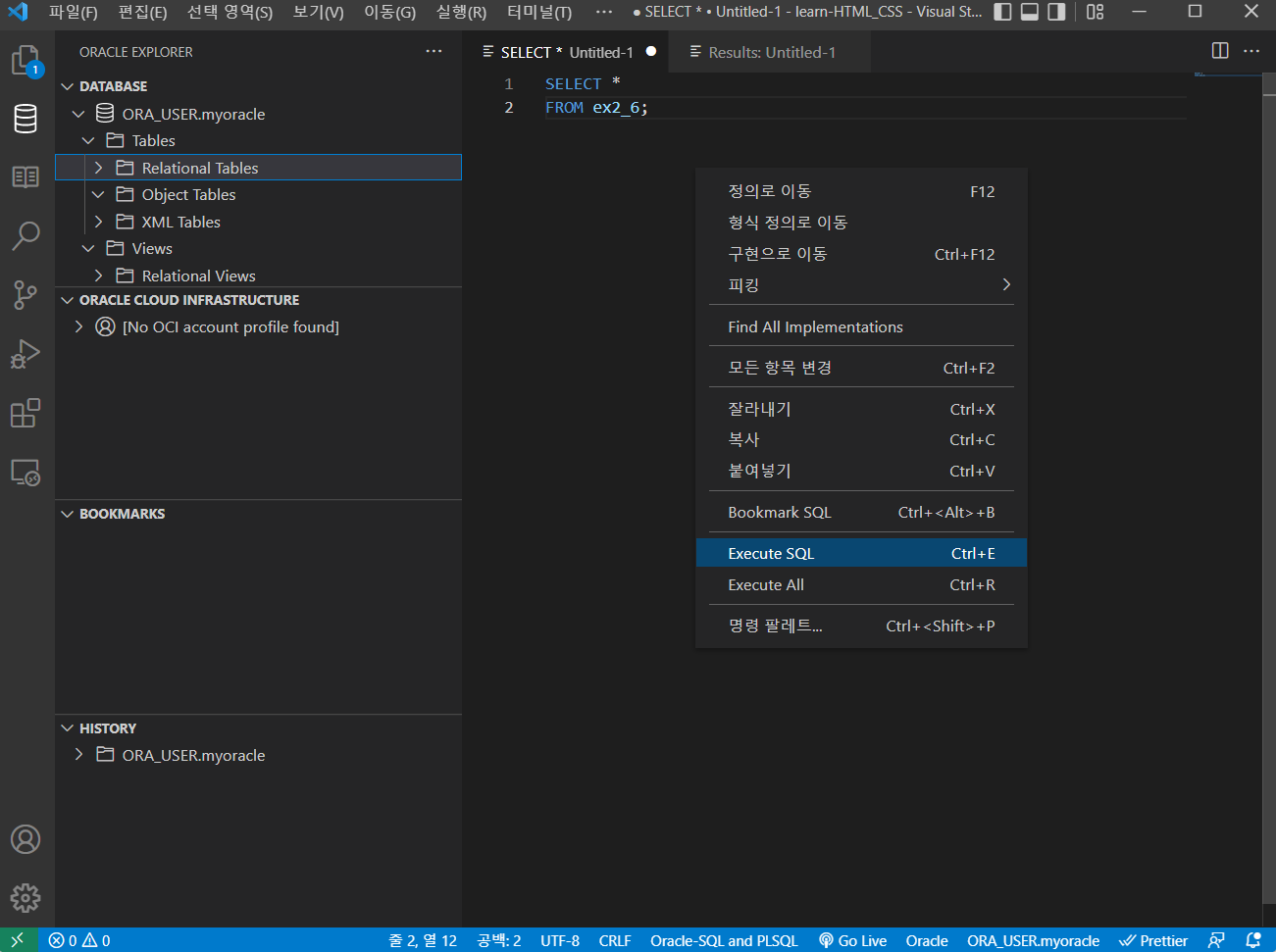
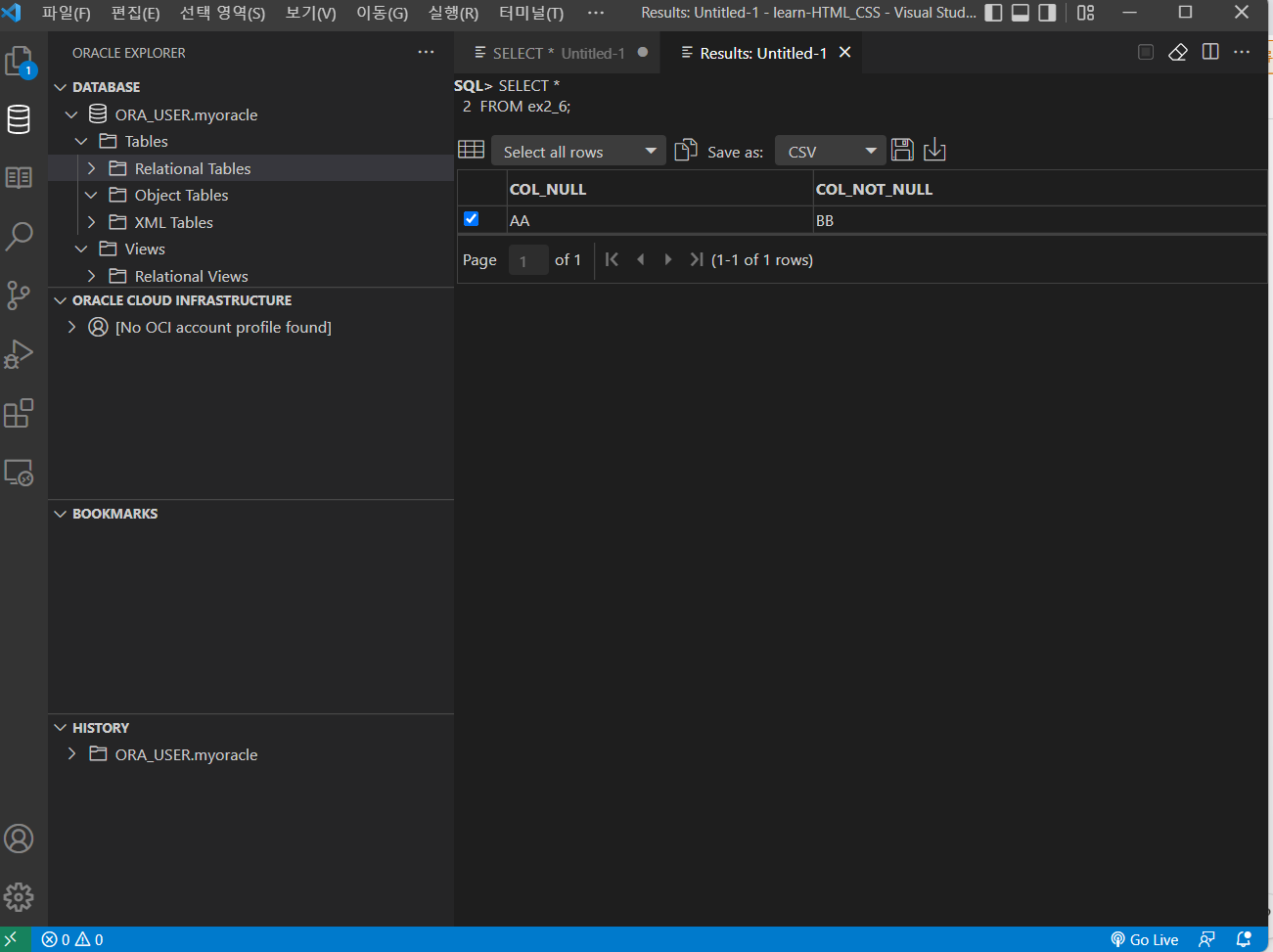
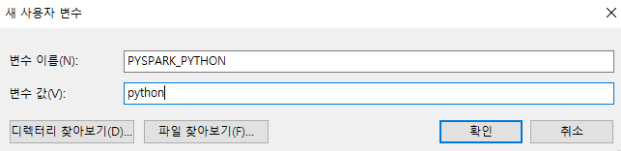
이 글은 https://velog.io/@ansfls/Heroku로-간단하게-웹-사이트-배포하기 사이트를 참고하여 작성되었습니다.
개요
- Heroku를 이용하여 웹 사이트에 내 프로젝트 소스를 배포를 하는 방법을 설명한다.
Heroku란
- Java, Node.js, Python 등 여러 언어를 지원하는 Paas (Platform-as-a-service) 클라우드 서비스로 간단한 클라우드 기반의 어플리케이션 플랫폼이다.
- Paas (Platform-as-a-service)란
Step 1. Heroku 가입 및 App 생성
- 아래 링크를 통해 회원가입을 한다.
아래 사진 처럼 두개의 탭이 보이는데
Create a new app탭을 클릭한다.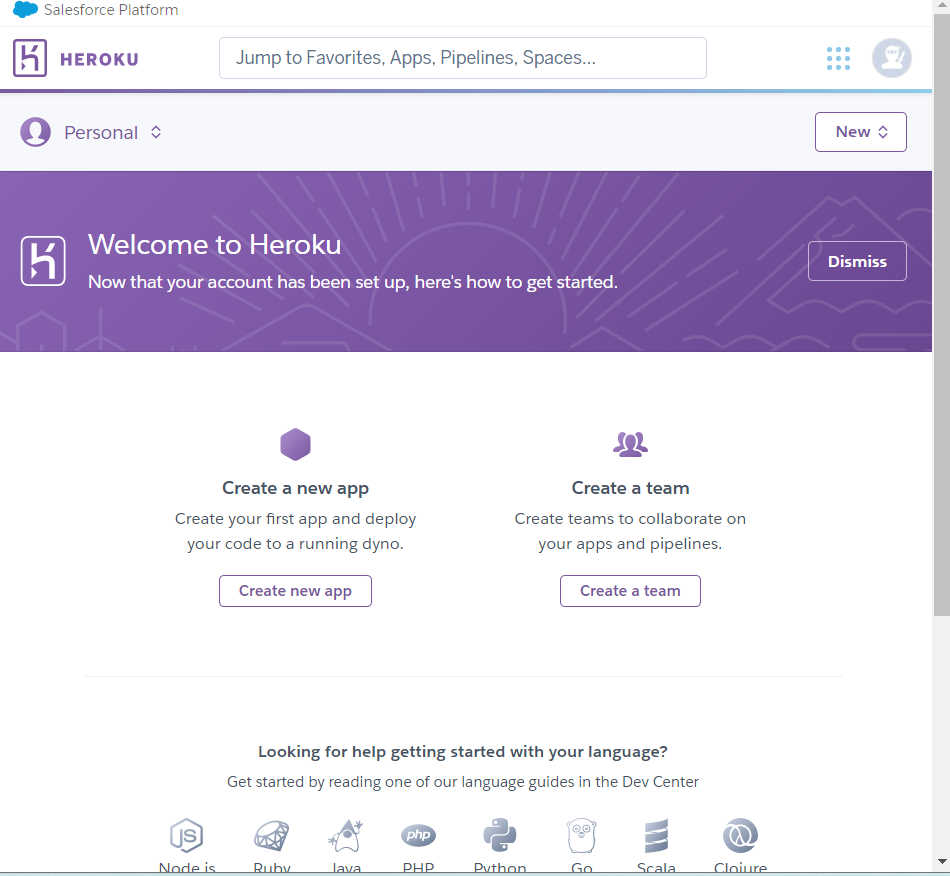
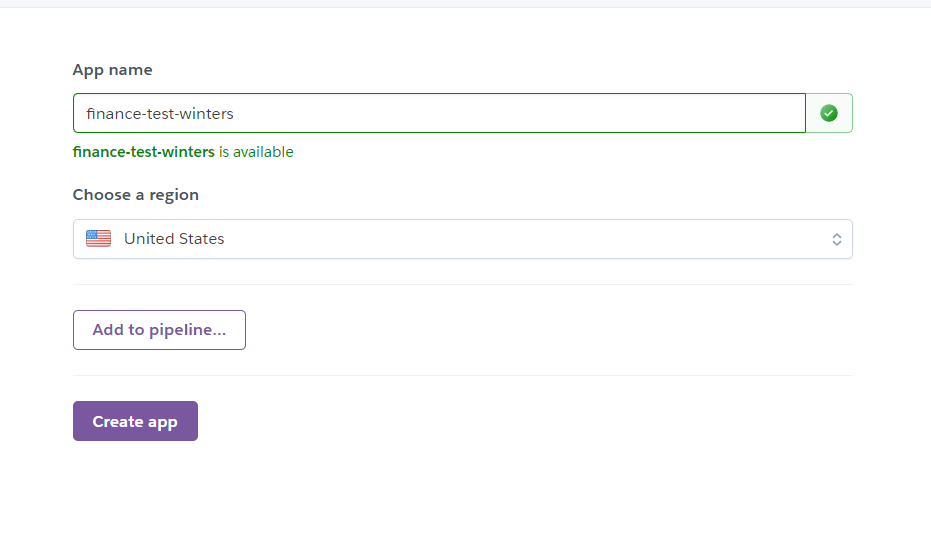
App name 설정 및 region을 United States로 설정한다.(무료 이용을 하려면 지역을 United States로 해야한다.)
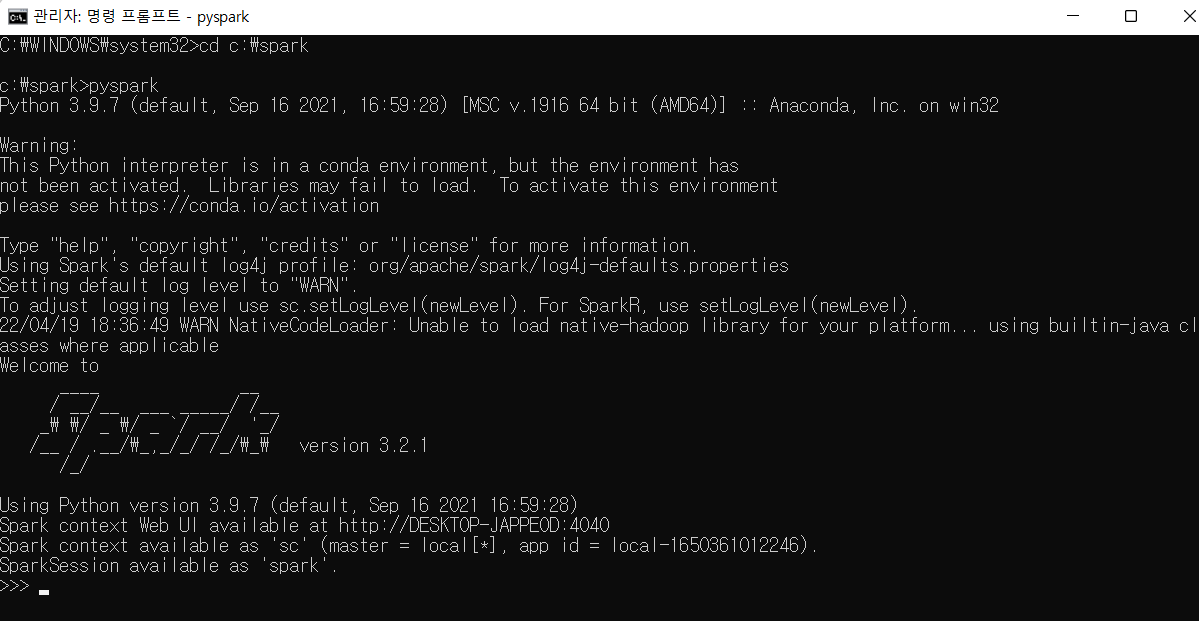
Step 2. Heroku CLI 설치
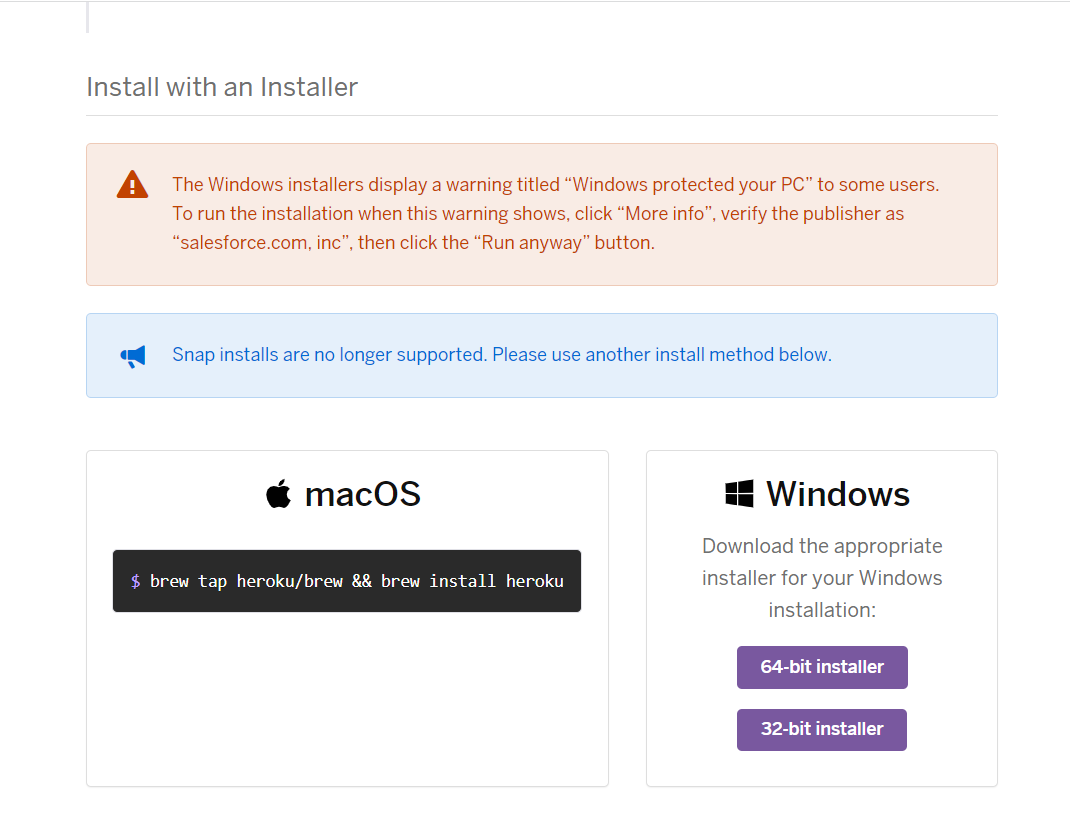
- 이제 Heroku에 내 프로젝트 소스를 올리기 위해 Heroku CLI를 아래 링크를 통해 설치해줘야 한다. (사용 중인 OS에 맞게 다운로드 해서 설치하면 된다)
- Heroku CLI 링크 : https://devcenter.heroku.com/articles/heroku-cli
- Heroku CLI 링크 : https://devcenter.heroku.com/articles/heroku-cli
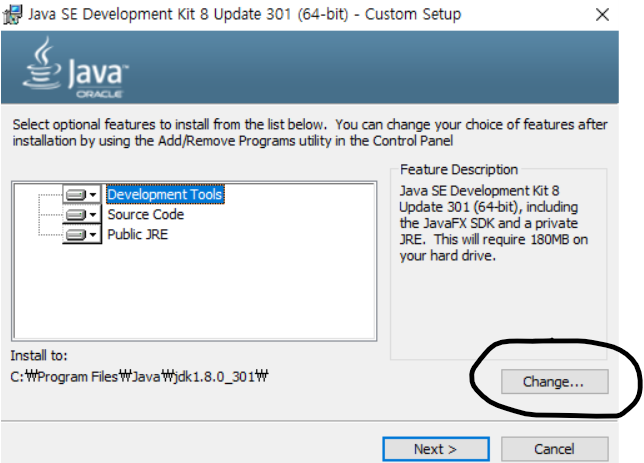
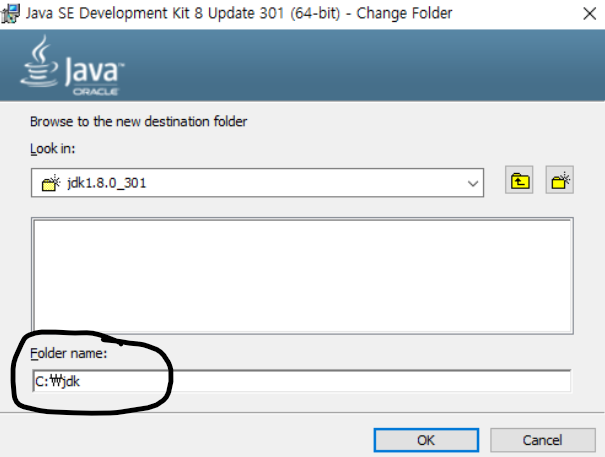
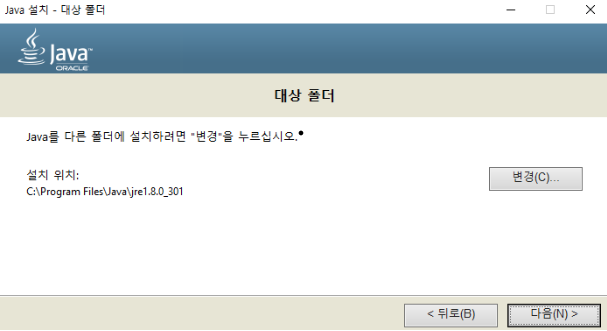
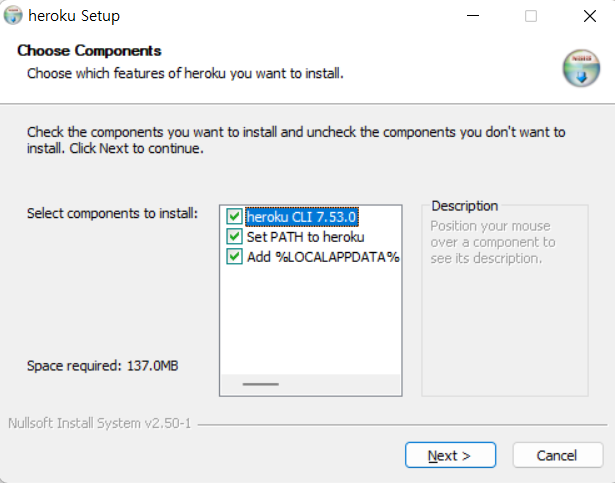
관리자 권한으로 실행하여 아래 체크 박스를 모두 체크한 뒤 next를 눌러 다운로드 받아준다.
- 관리자 프롬프트(CMD)나 각 터미널을 실행하여 설치가 잘 되었는지 확인한다. ( 필자는 VS Code를 이용하여 Gitbash 터미널을 사용하였다.)
1
heroku --version

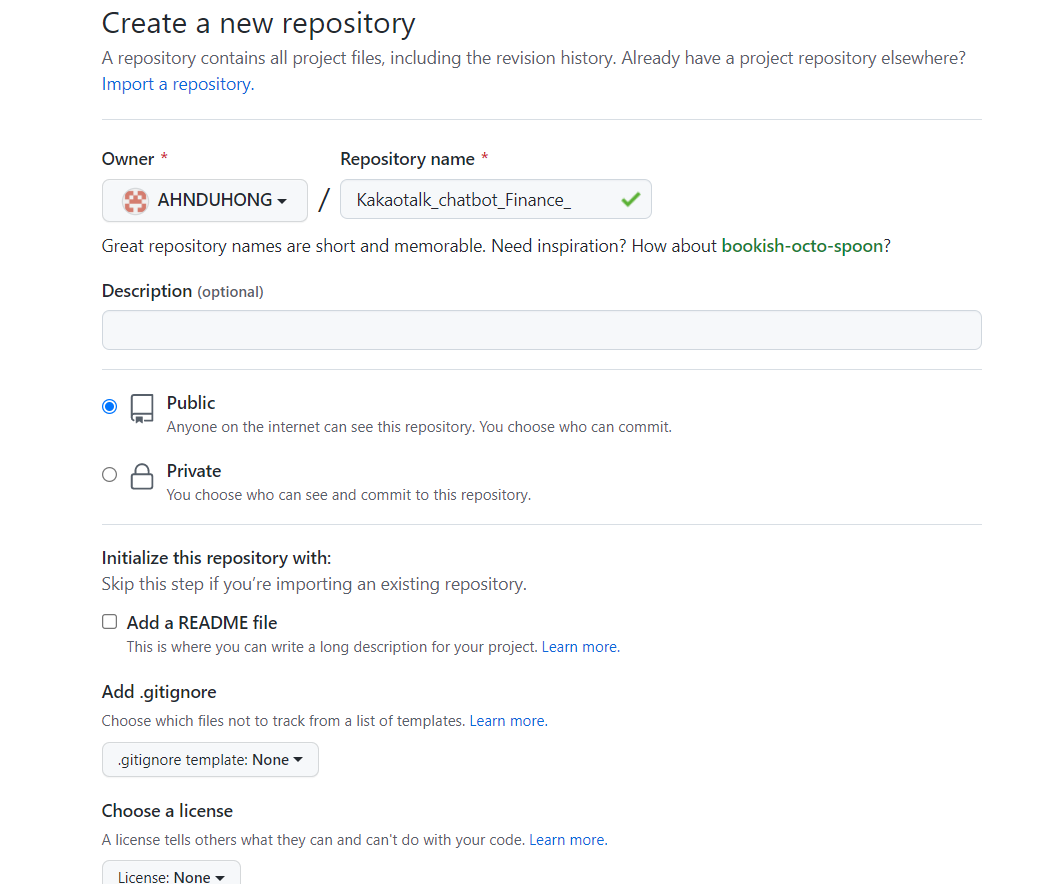
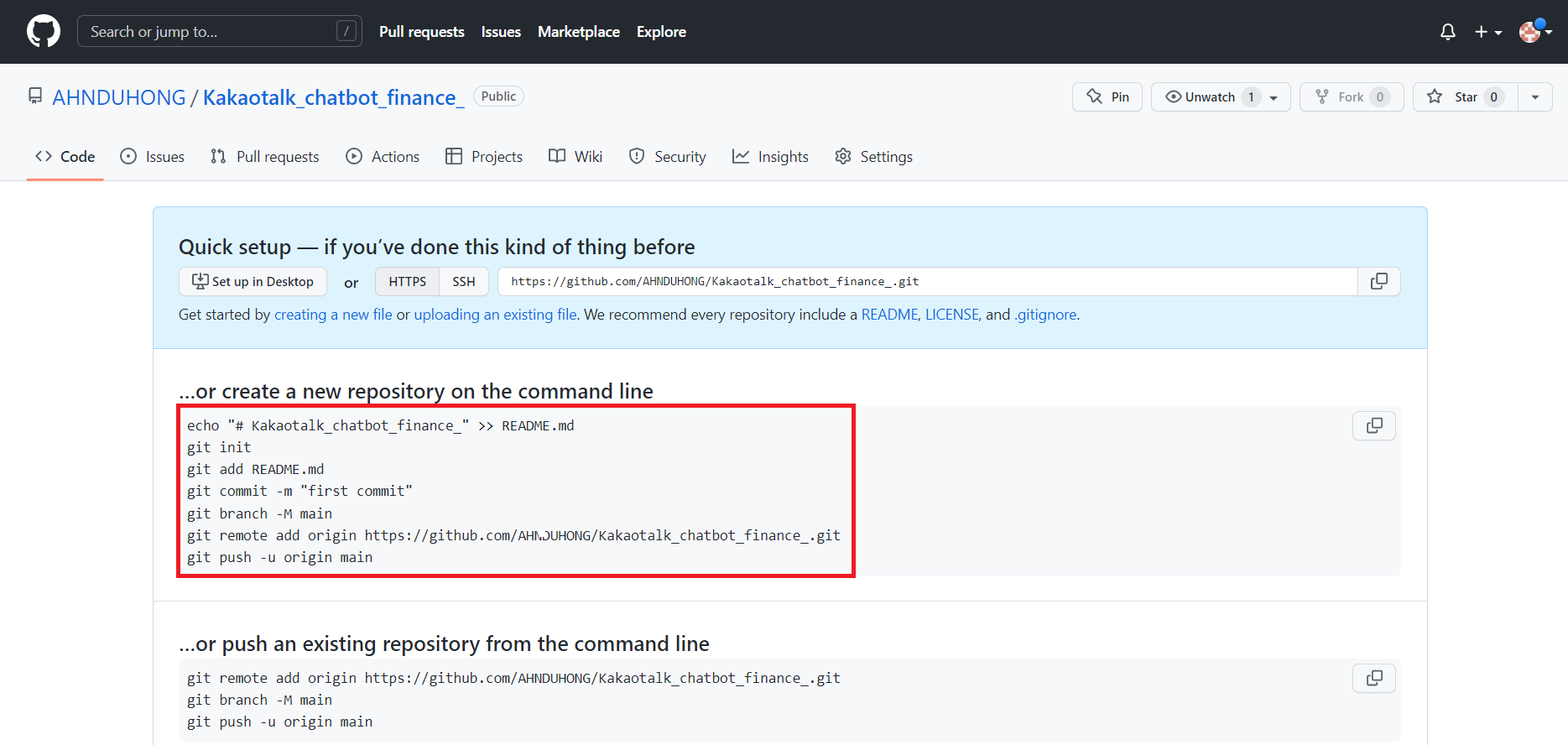
Step 3 Github Repository 생성
- Github 페이지로 들어가 Repository를 생성하여 이름을 Heroku에서 생성한 App 이름과 같이 작성한다.
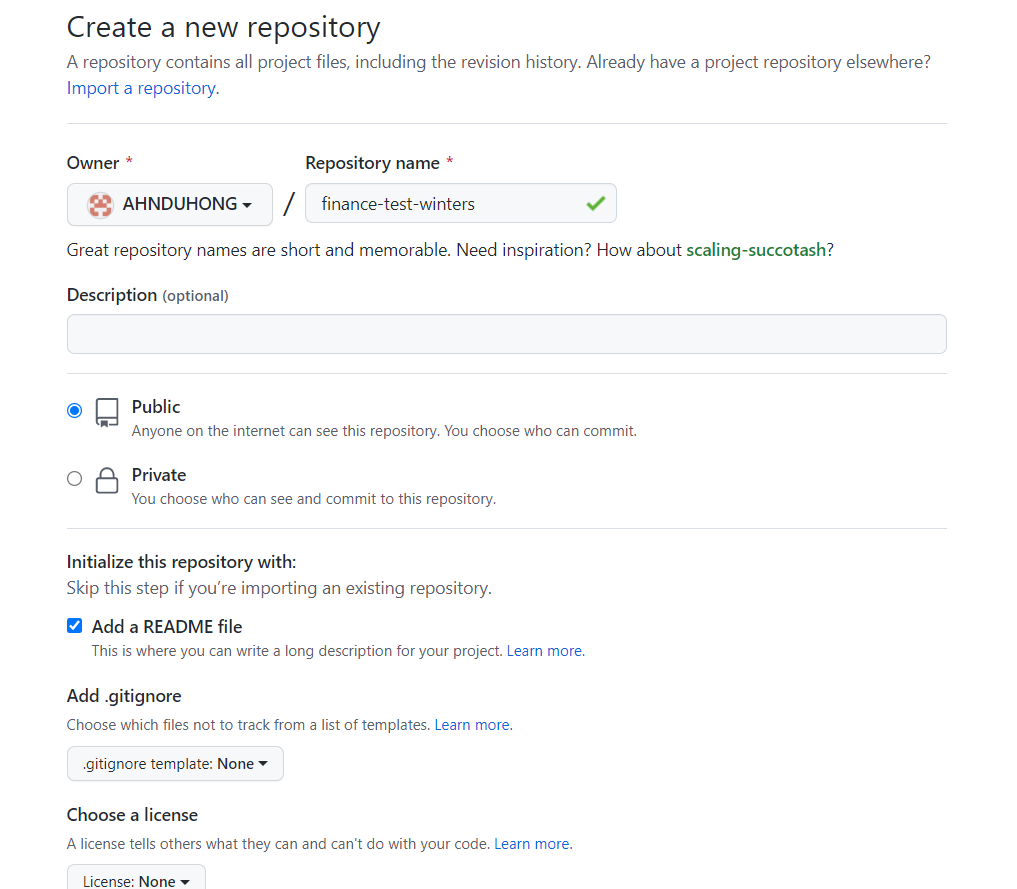
Step 4. Heroku 로그인 및 배포
- 위에서 실행했던 터미널에 아래 코드를 입력하여 Heroku 로그인을 진행한다.
1
$ heroku login

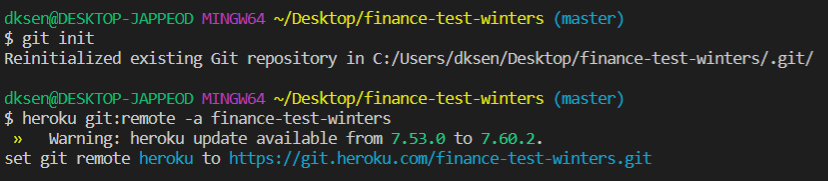
경로를 생성한 프로젝트의 폴더로 이동한 뒤 다음 명령어를 통해 git repository를 연결한다.
1
2$ git init
$ heroku git:remote -a <app-name>
아래와 같이
Method Not Allowed가 나오면 정상이다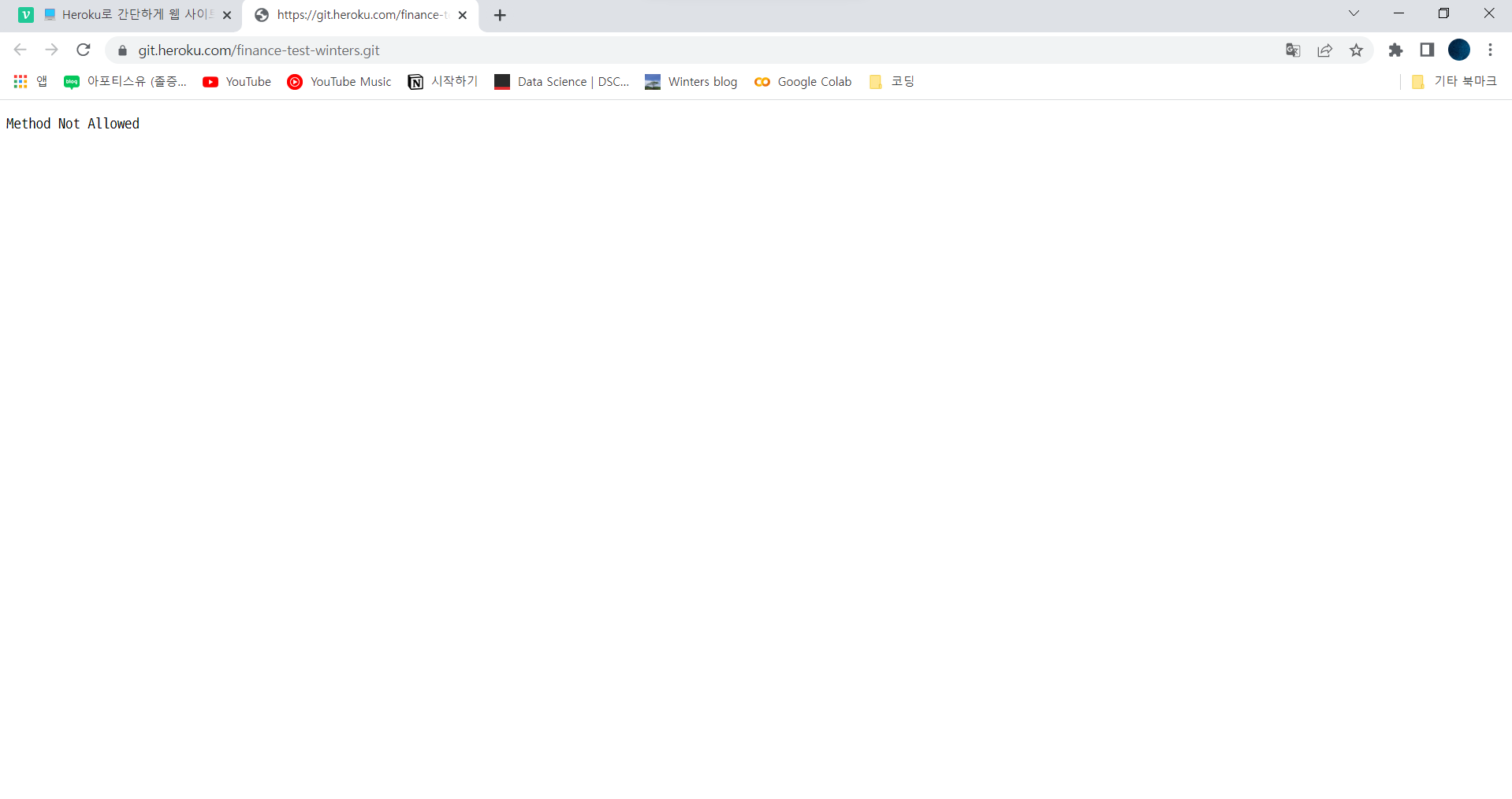
git 사용법과 동일하게 프로젝트를
add→commit→push한다.1
2
3
4$ git add .
$ git commit -am "first commit"
$ git push heroku master
# git push 에서 에러가 발생한다면 git push heroku HEAD:master로 하길
Verifying deploy... done.메세지가 나오면 정상적으로 Git 연동 완료
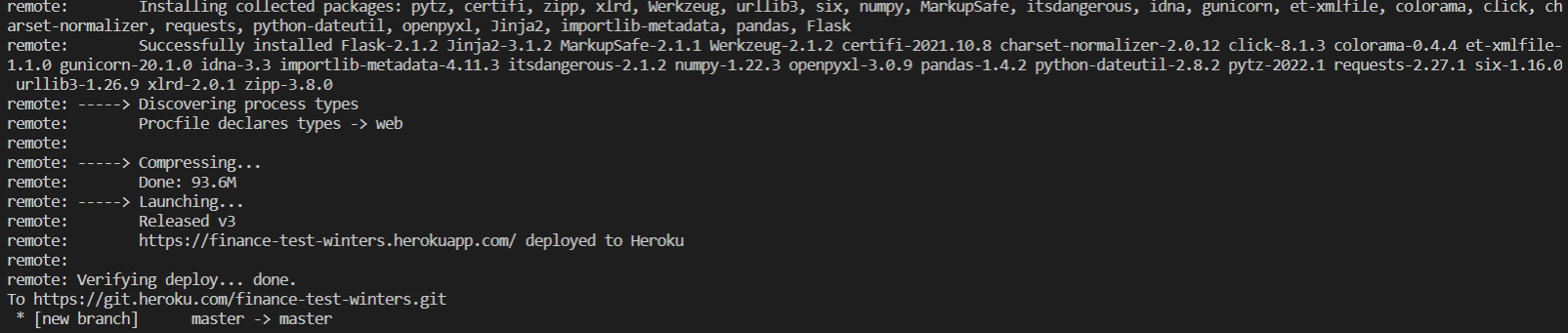
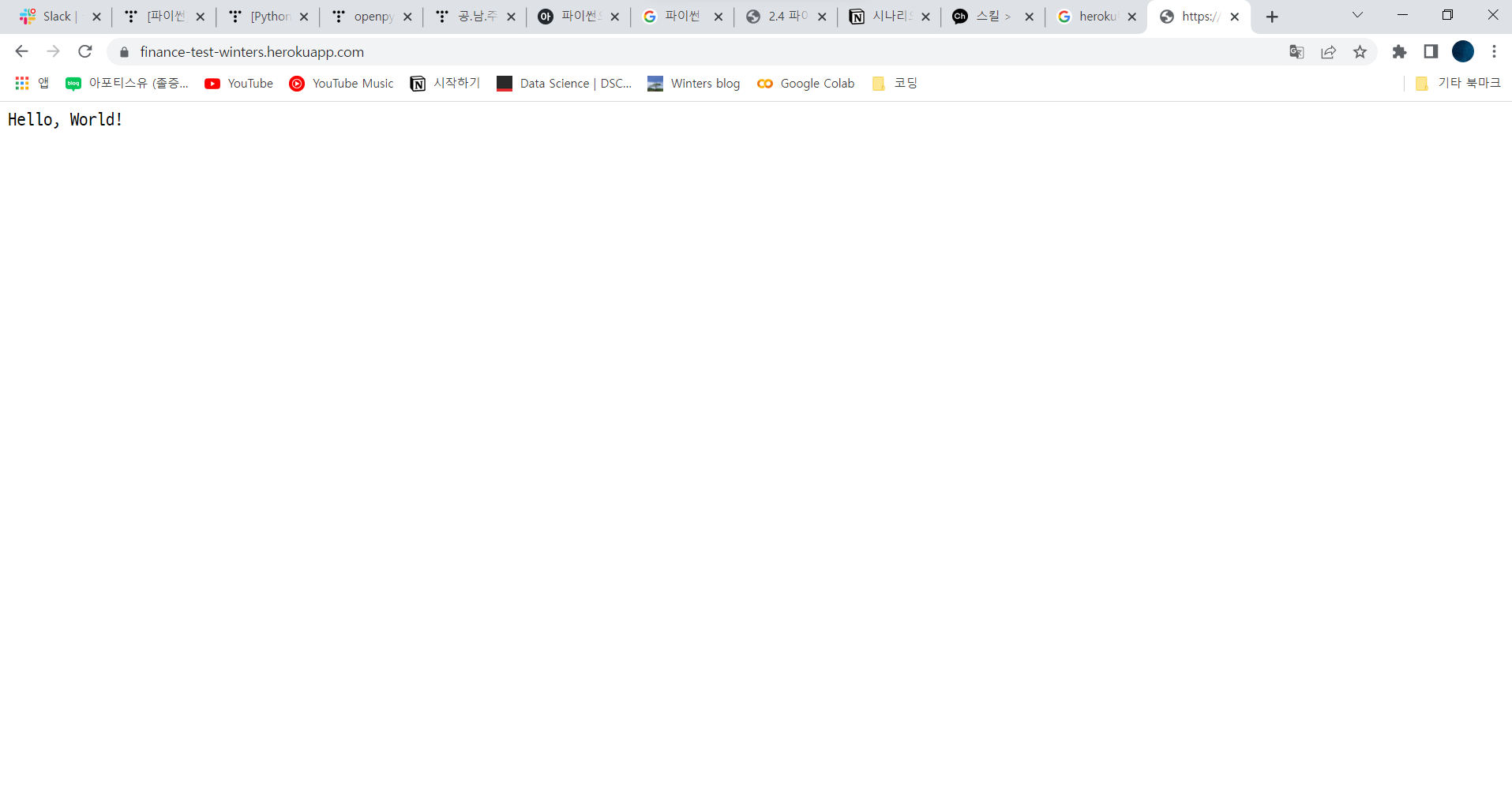
Step 5. 웹상 확인
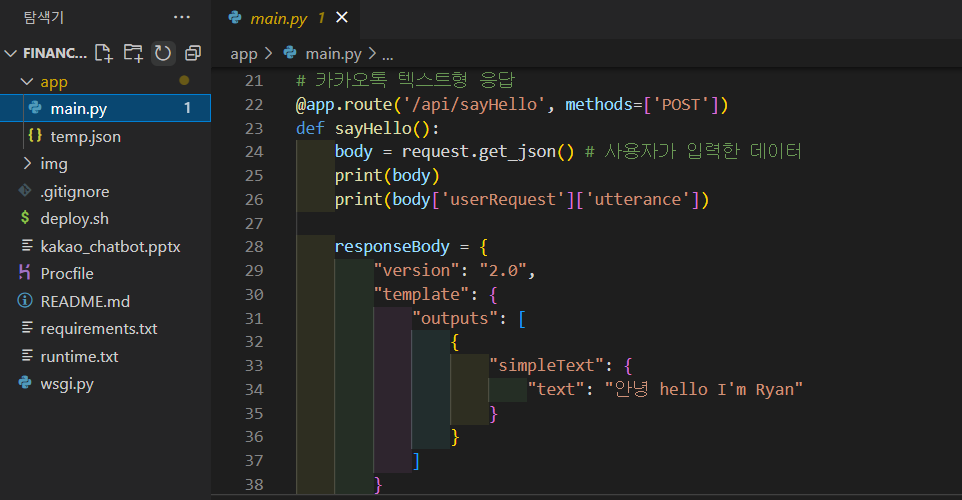
- 만든 App Name을 아래 주소를 이용하여 맞게 수정하여 확인 (필자는 main.py에 만든 로직을 통하여 Hello world! 를 출력하도록 설정함)