from sklearn.preprocessing import StandardScaler ss = StandardScaler() ss.fit(train_input)
# ss 훈련 데이터만 활용해서 학습(?)이 끝난 상태 # 표준화 처리를 훈련 데이터와 테스트 데이터에 동시 적용 train_scaled = ss.transform(train_input) test_scaled = ss.transform(test_input)
모델 학습
2개의 매개 변수 지정
loss = “log” = 로지스틱 손실 함수로 지정
max_iter = 에포크 횟수 지정
에포크란(epoch)_01 : 훈련 데이터셋에 포함된 모든 데이터들이 한 번씩 모델을 통과한 횟수로, 모든 학습 데이터셋을 학습하는 횟수
에포크란_02 : 1 epoch는 전체 학습 데이터셋이 한 신경망에 적용되어 순전파와 역전파를 통해 신경망을 한 번 통과했다는 의미가 된다, 즉 epoch가 10회라면, 학습 데이터 셋 A를 10회 모델에 학습시켰다는 것
에포크란_03 : epoch를 높일수록, 다양한 무작위 가중치로 학습을 해보므로, 적합한 파라미터를 찾을 확률이 올라간다.(즉, 손실 값이 내려가게 된다.) 하지만 지나치게 epoch를 높이게 되면, 그 학습 데이터셋에 과적합되어 다른데이터에 대해선 제대로 된 예측을 하지 못할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from sklearn.linear_model import SGDClassifier
# 매개변수 지정 # 하이퍼파라미터 설정 ## 매개변수 값을 dictionary 형태로 추가하는 코드 작성 가능 ## 강사는 입문자들에게는 비추천 sc = SGDClassifier(loss = "log", max_iter = 40, random_state = 42)
# 모형 학습 sc.fit(train_scaled, train_target)
# 스코어 확인 (정확도) print(sc.score(train_scaled, train_target)) print(sc.score(test_scaled, test_target)) # 샘플링의 차이로 값이 일정하지 않고 다를 수 있다.
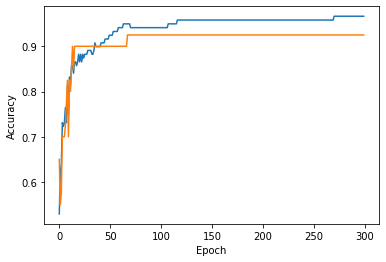
fig, ax = plt.subplots() ax.plot(train_score) ax.plot(test_score) ax.set_xlabel("Epoch") ax.set_ylabel("Accuracy") plt.show() # 파란색 훈련, 노란색 테스트 # 훈련데이터가 안정화되고 테스트데이터도 안정화되면서 가까운 곳은 epoch가 100일때의 지점이라고 알 수 있음.