작성한 SQL 파일 및 코드들을 Jupyter Notebook에서 실행 하기 위한 설정하는 과정을 설명한다.
필자는 평소 Jupyter Notebook을 VSCode로 실행하여 VSCode를 통해 설명을 하는데 Jupyter Lab 또는 Jupyter Notebook을 직접 실행하여 설정해도 무방하다.
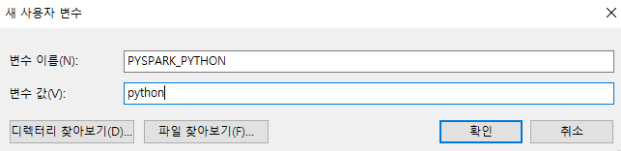
Step 1. 라이브러리 설치
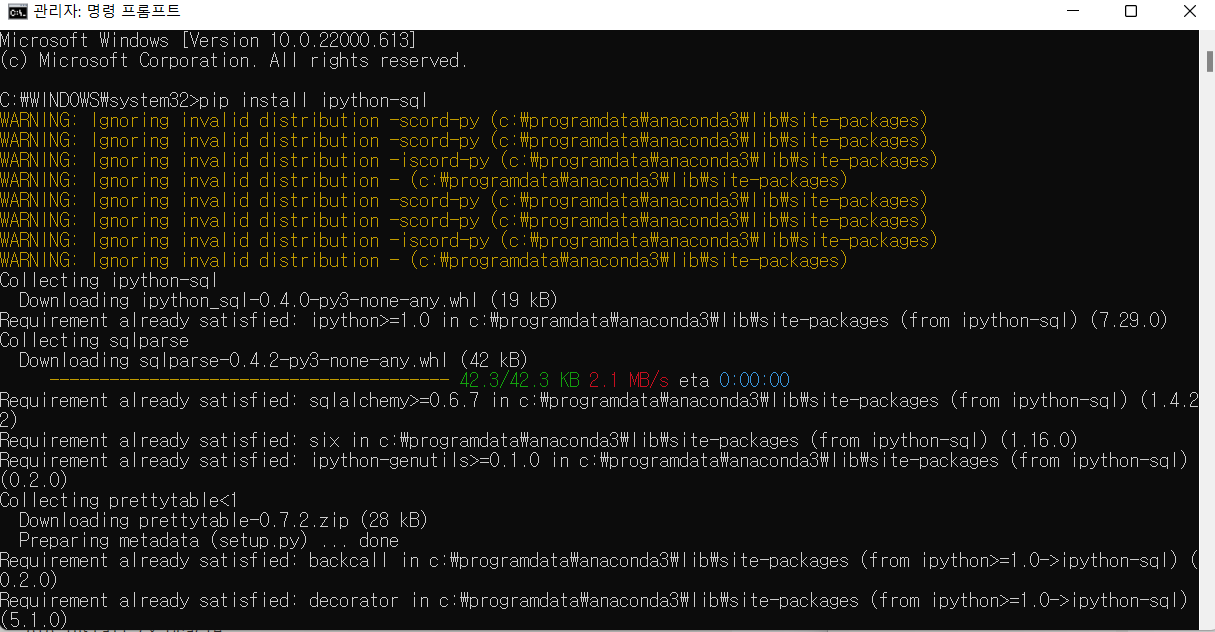
공통적으로 다음 라이브러리를 설치한다.
1
pip install ipython-sql
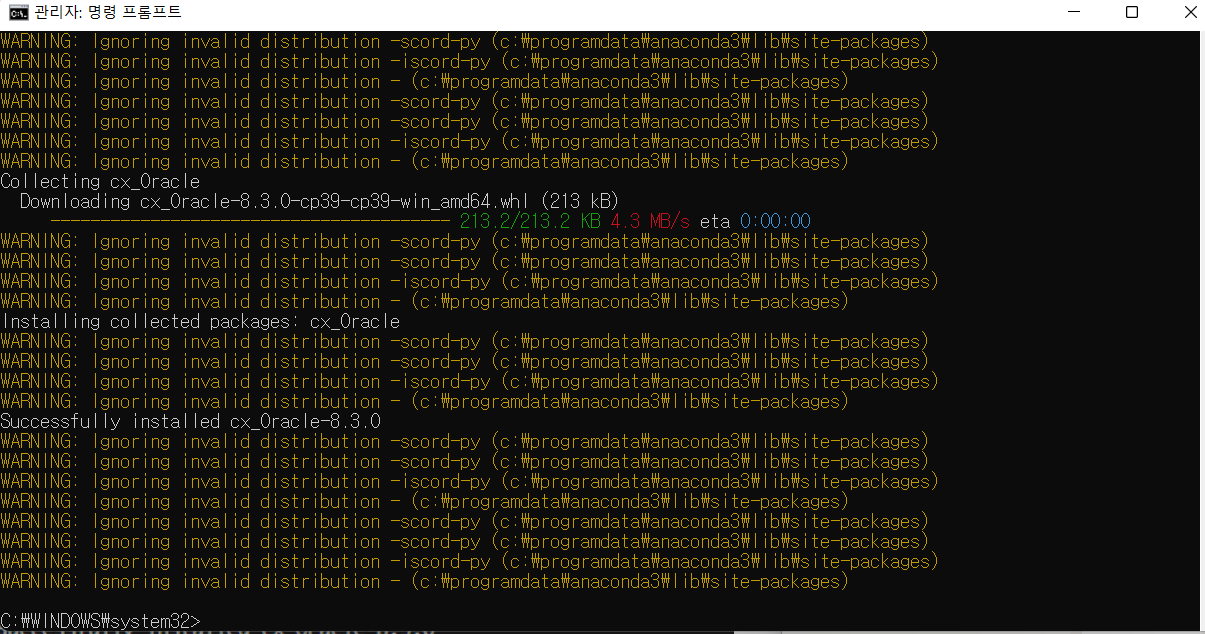
다음으로 접속하려는 DB에 맞춰서 라이브러리를 설치한다.
1 2 3 4 5 6 7 8 9 10 11
# sql server pip install pyodbc
# PostgreSQL pip install pyscopg2
# MySQL pip install PyMySQL
# Oracle pip install cx_Oracle
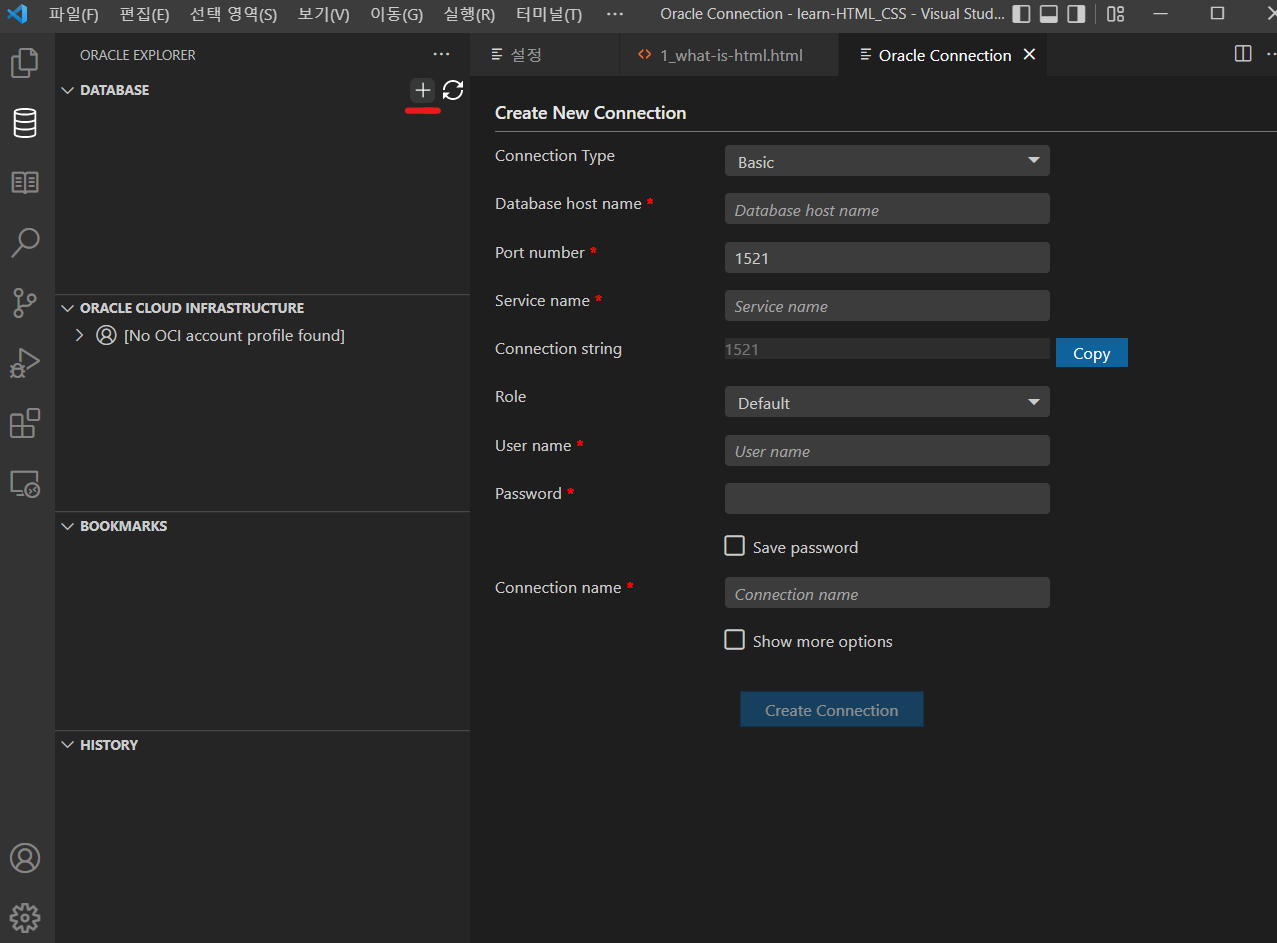
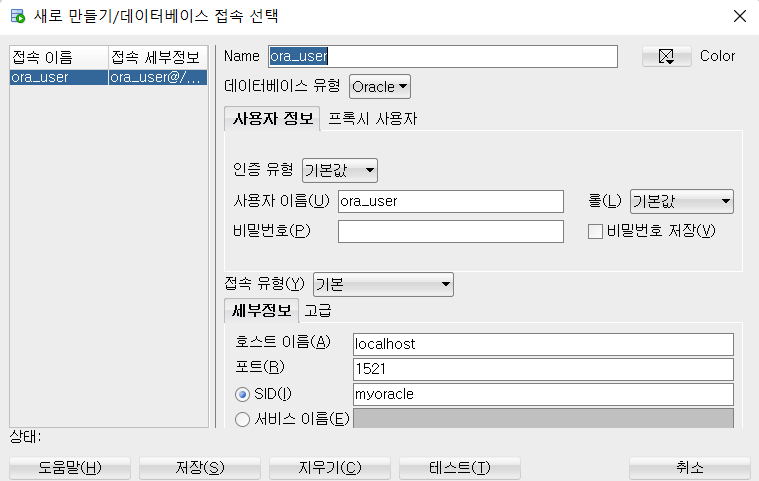
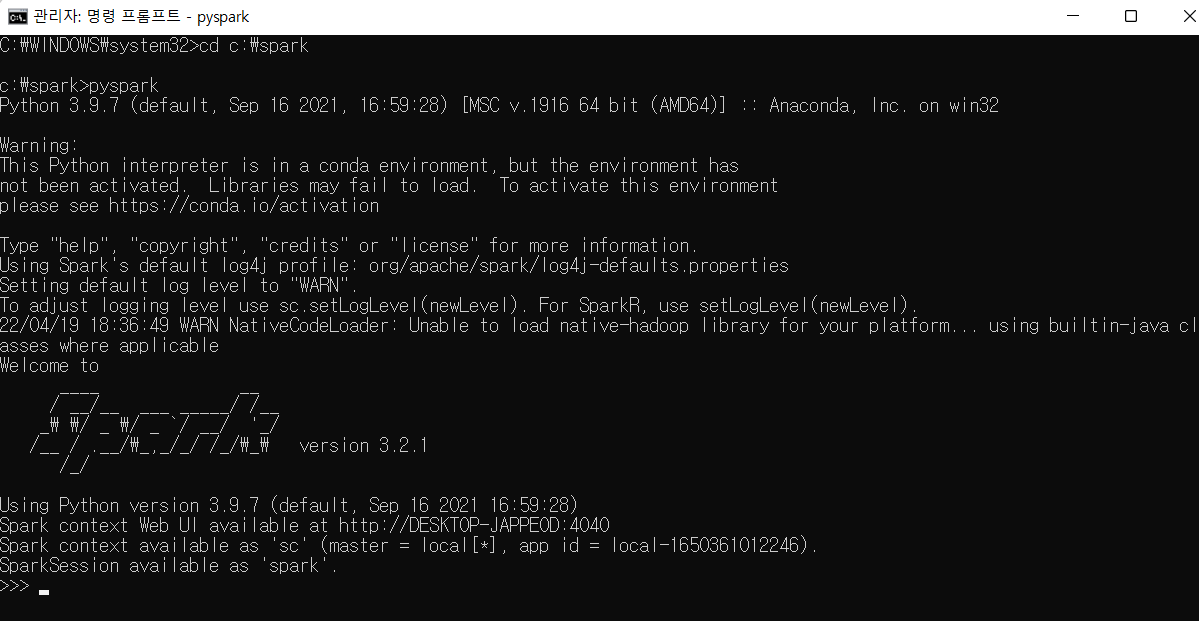
Step 2. Jupyter Notebook SQL 연결
필자는 VSCode를 사용하여 Jupyter Notebook을 사용하여 VSCode를 사용하여 작성하였다.
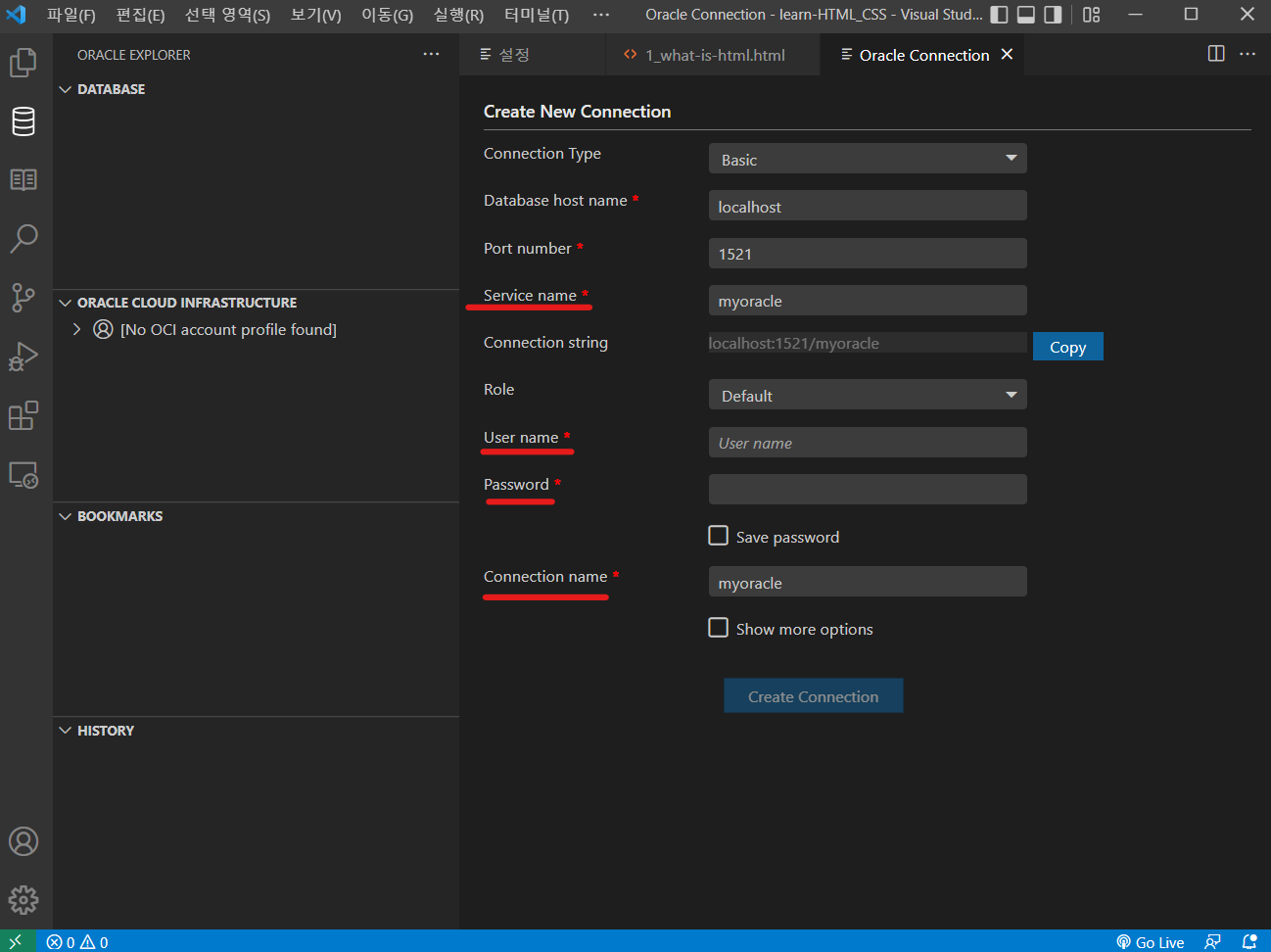
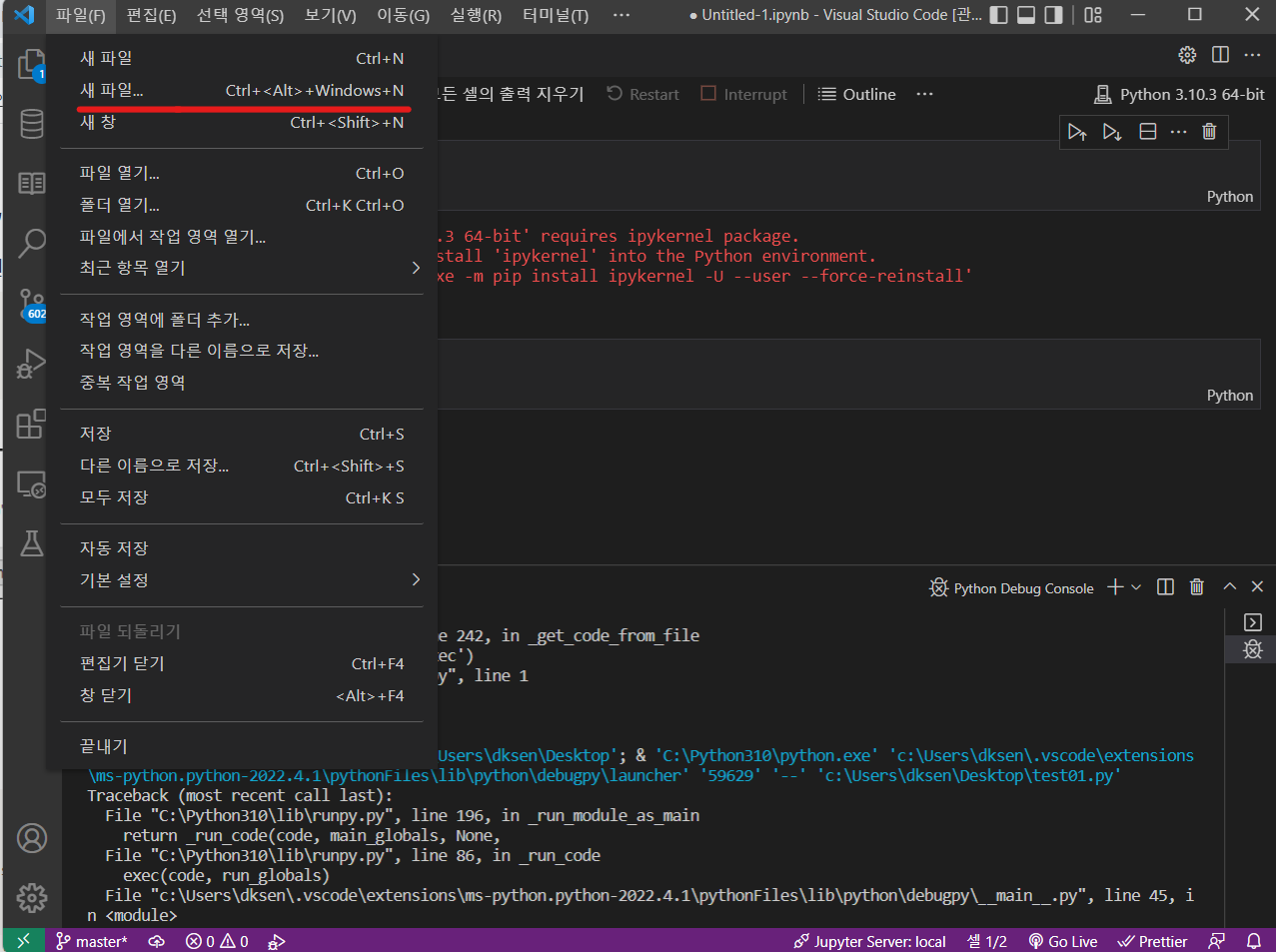
VScode를 실행하여 아래 사진에서 밑줄 친 새 파일을 클릭하면 Jupyter Notebook(.ipynb) 형식으로 파일을 생성한다.
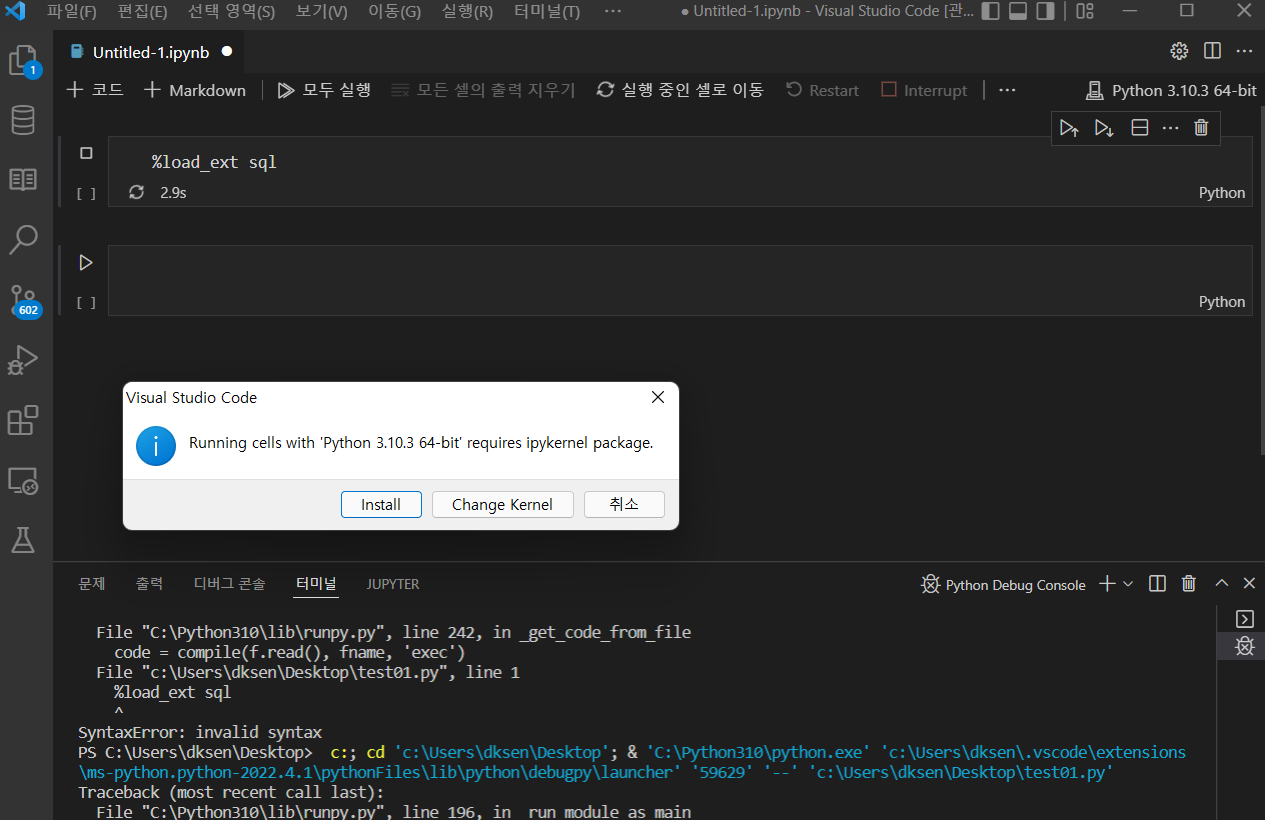
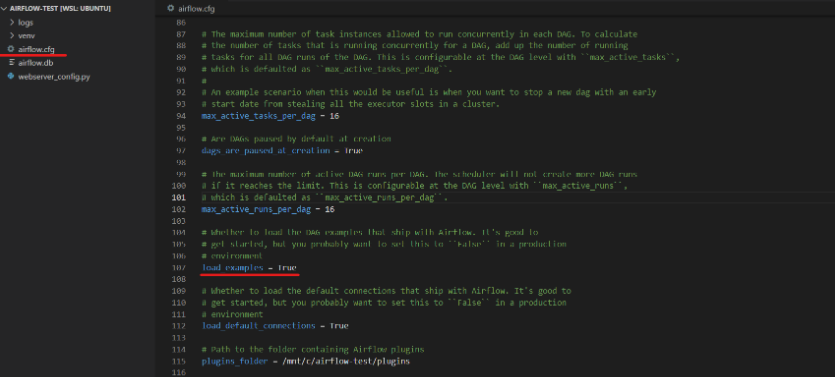
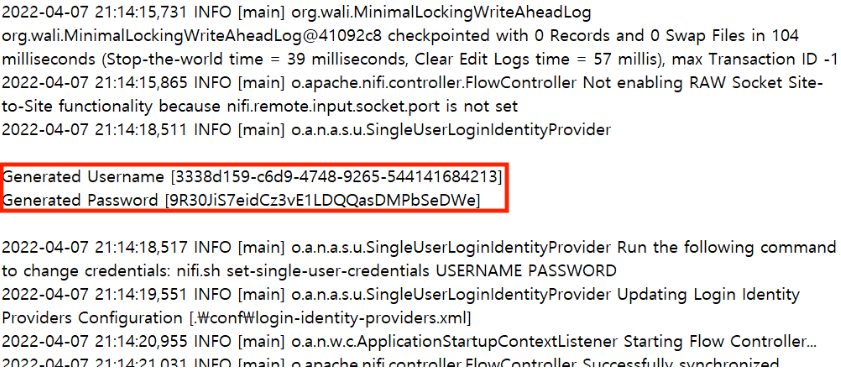
생성한 파일에 매직 명령어로 아래와 같은 코드를 입력한 뒤 실행하면 pakage 설치 안내창이 나오는데 설치한다.
1
%load_ext sql
모듈 에러(ModuleNotFoundError: No module named ‘sql’)
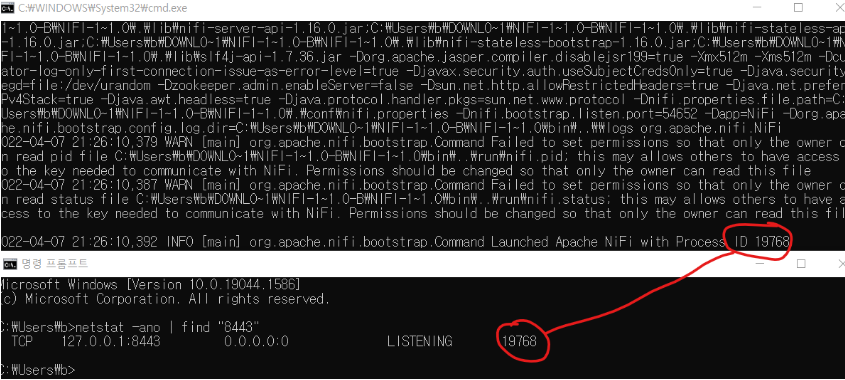
이 에러는 sql이라는 이름의 모듈을 설치가 안되었을때 나오는 에러인데 라이브러리를 설치를 해줬는데도 불구하고 ModuleNotFoundError: No module named 'sql' 라는 에러가 나온다. 그럴 땐 내가 설치를 한 라이브러리가 어느 경로에 저장되었는지 확인해야 한다. (필자는 설치를 할 때 나온 메세지를 통해 확인함.)
1 2
import sys sys.executable -- 현재 파일 파이썬 경로 확인
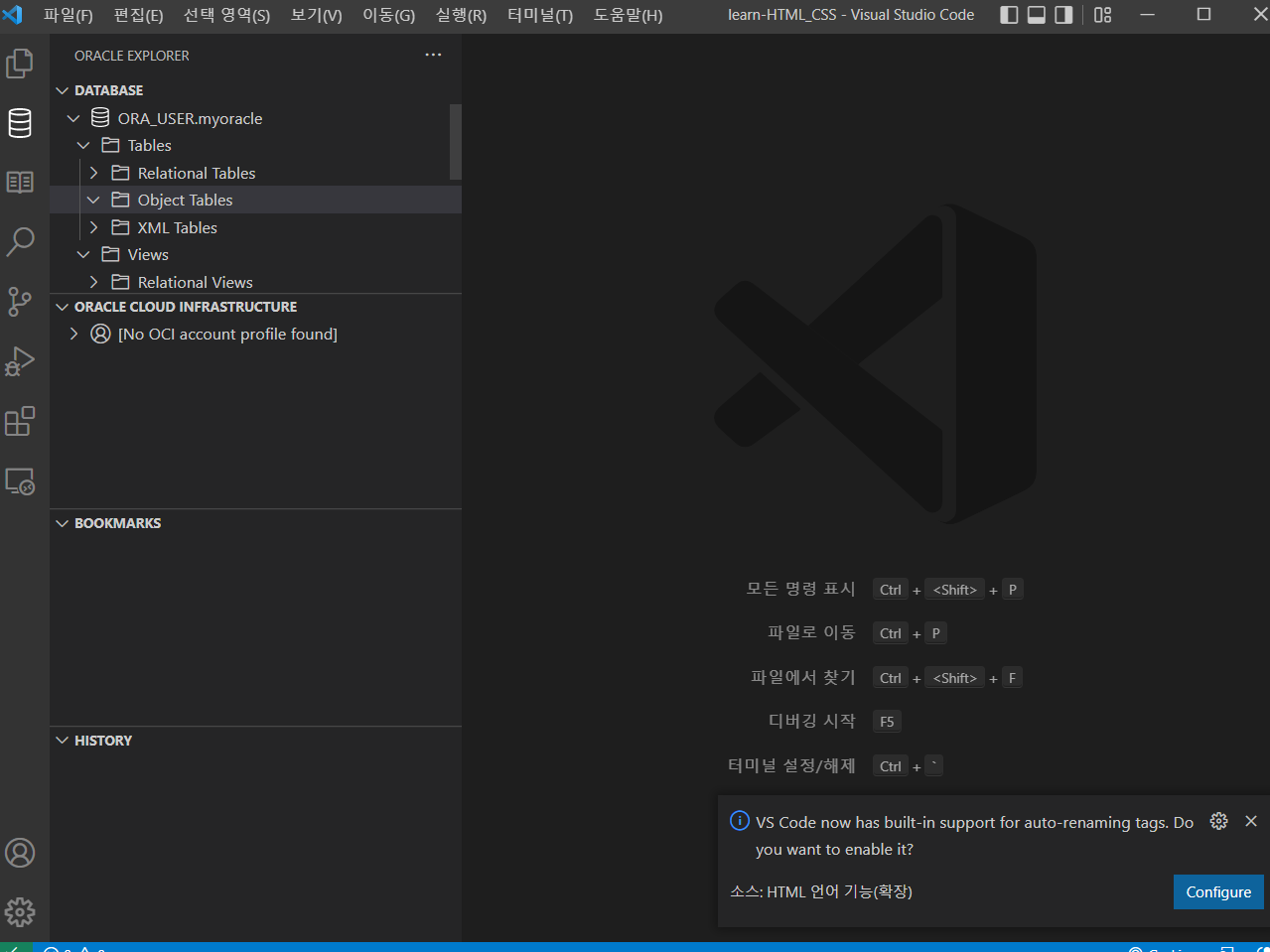
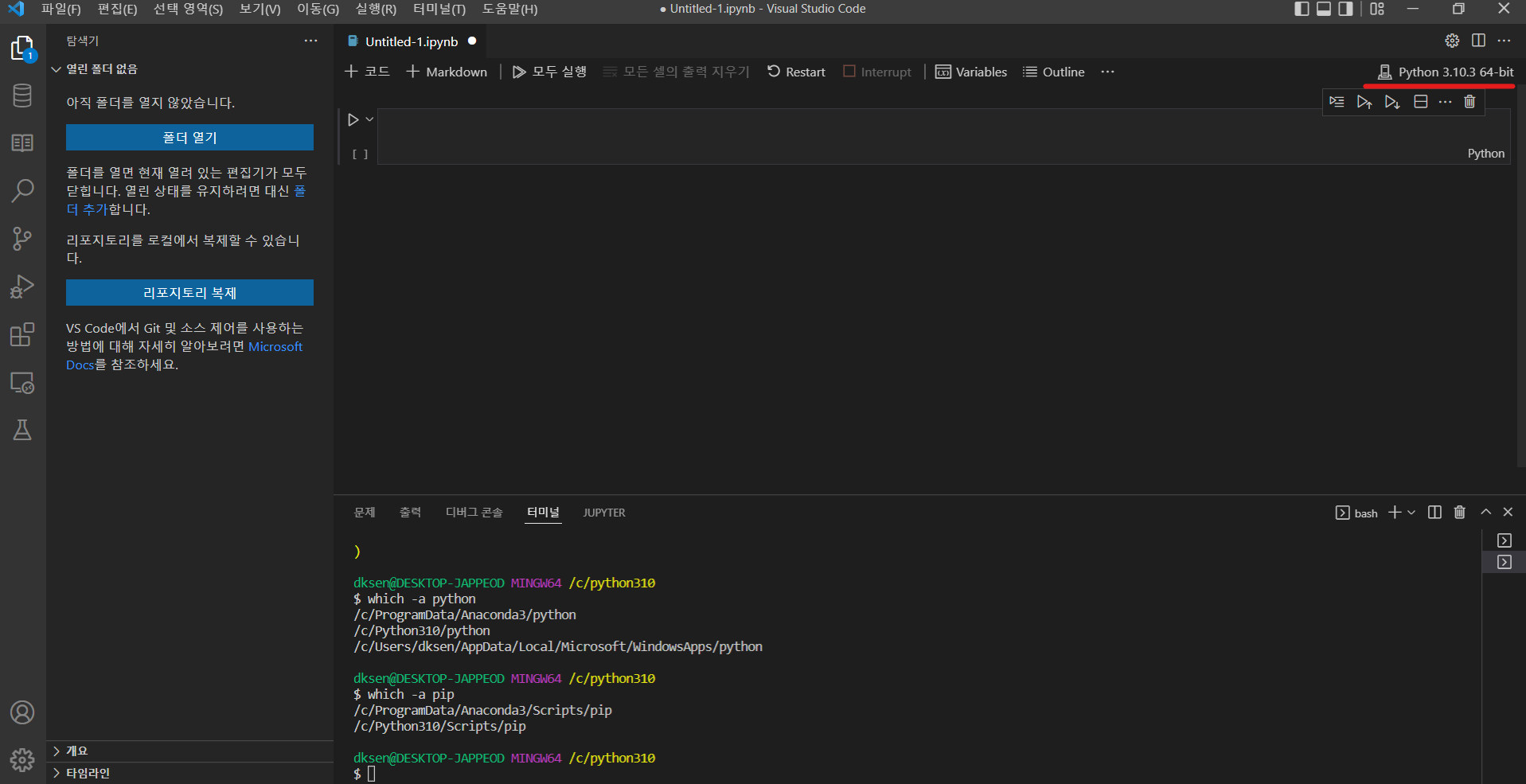
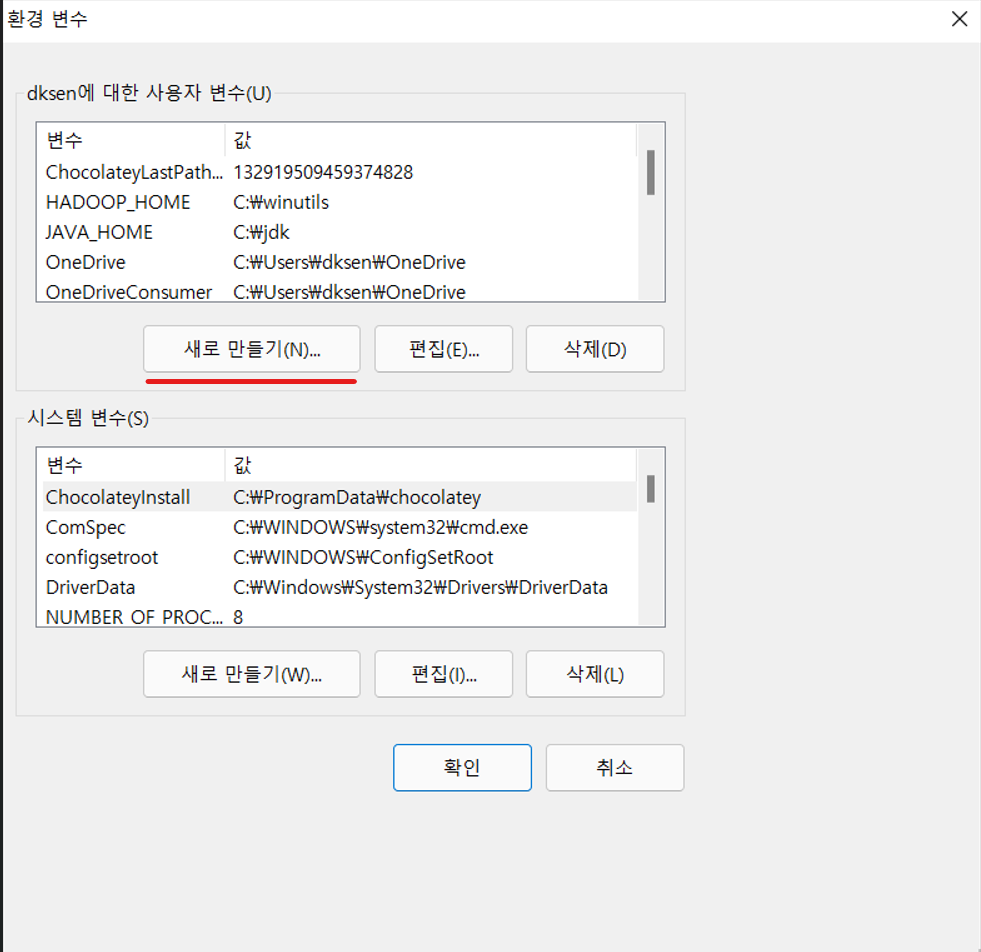
필자는 VSCode로 생성한 파일의 파이썬 경로와 다른 경로에 설치가 되어 위와 같은 오류가 생성되었던 것이다. 그렇다고 환경 변수를 새로 설정하기에는 너무 복잡하니, 파이썬 파일을 새로 만들어 설치된 경로와 맞춰주겠다.
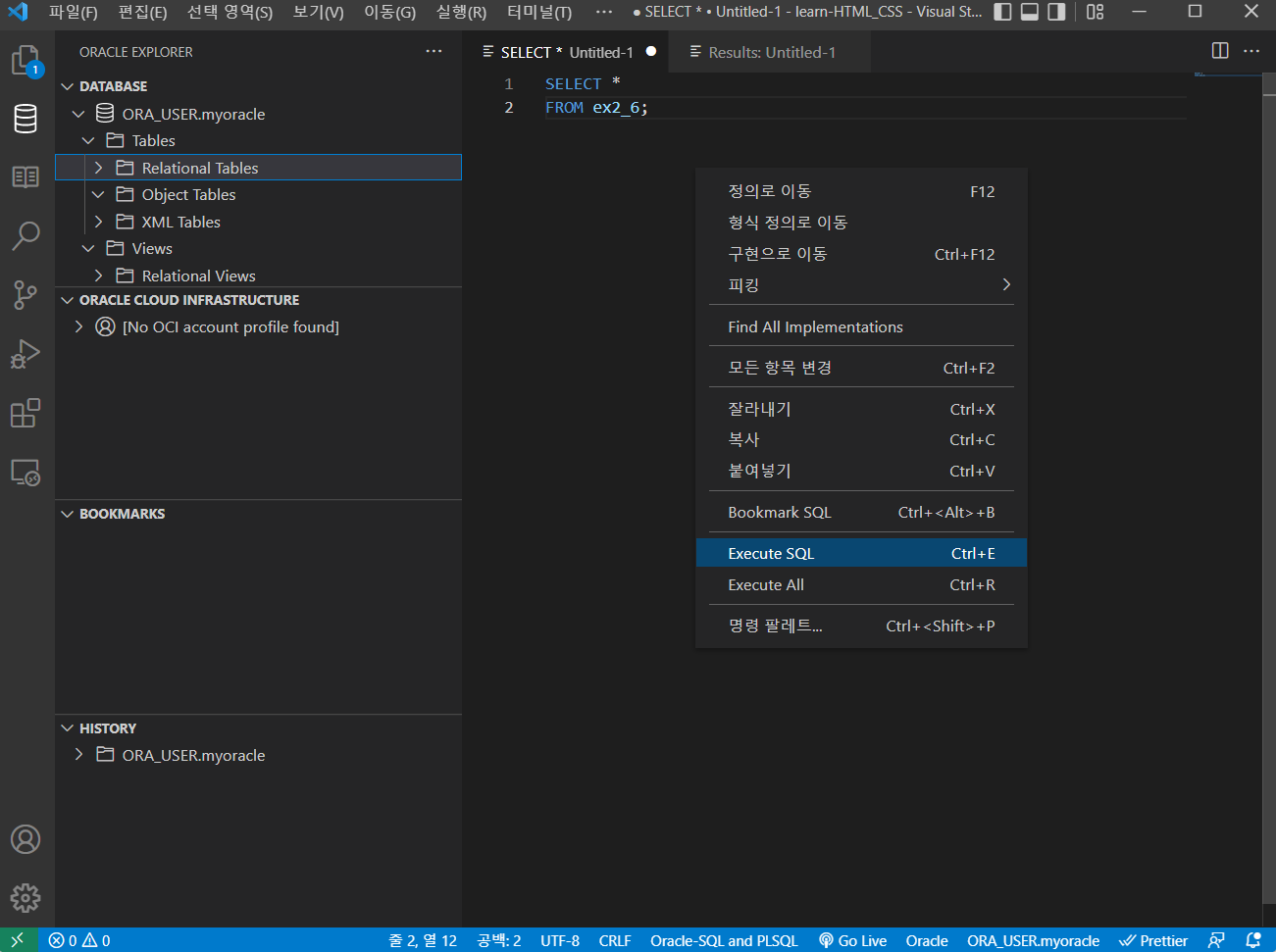
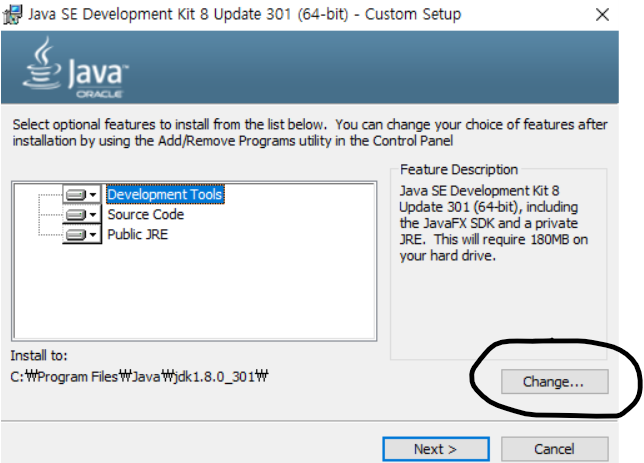
아래 사진 우측 상단에 밑줄 친 상자 클릭을 한다.
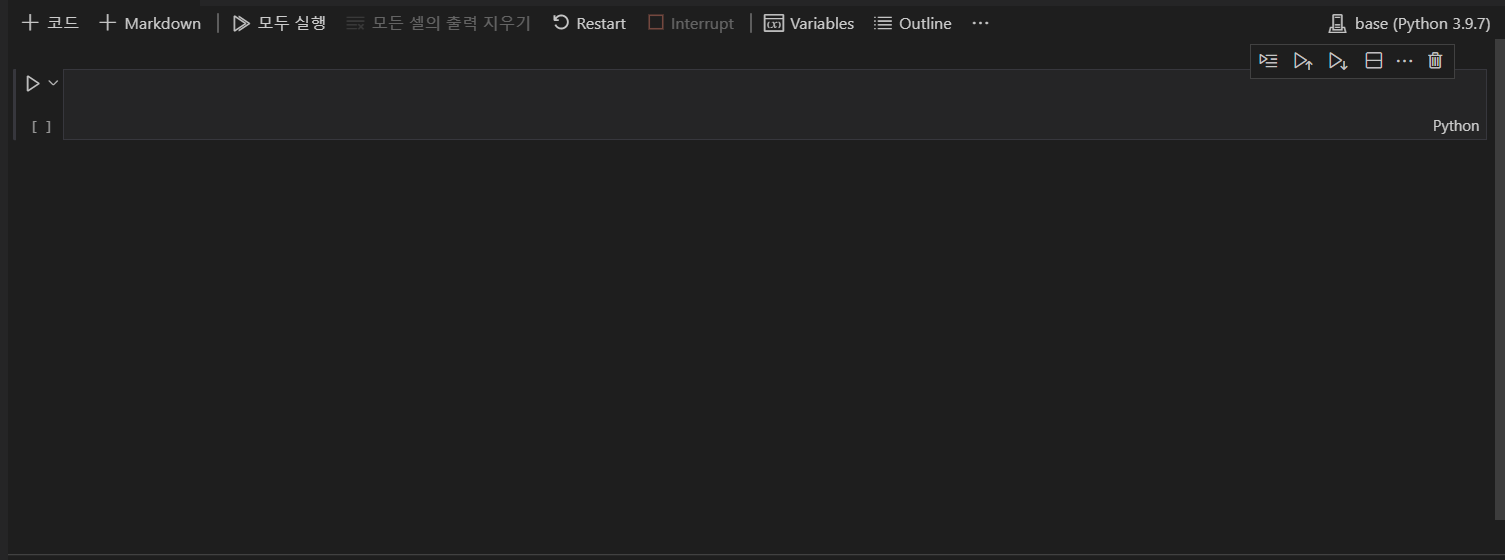
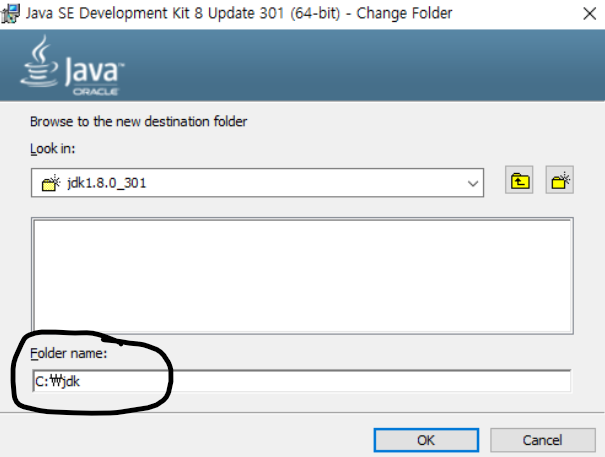
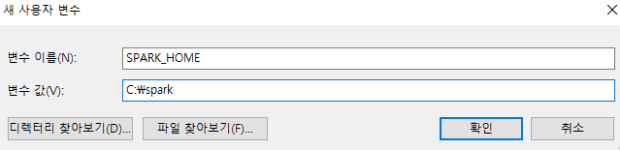
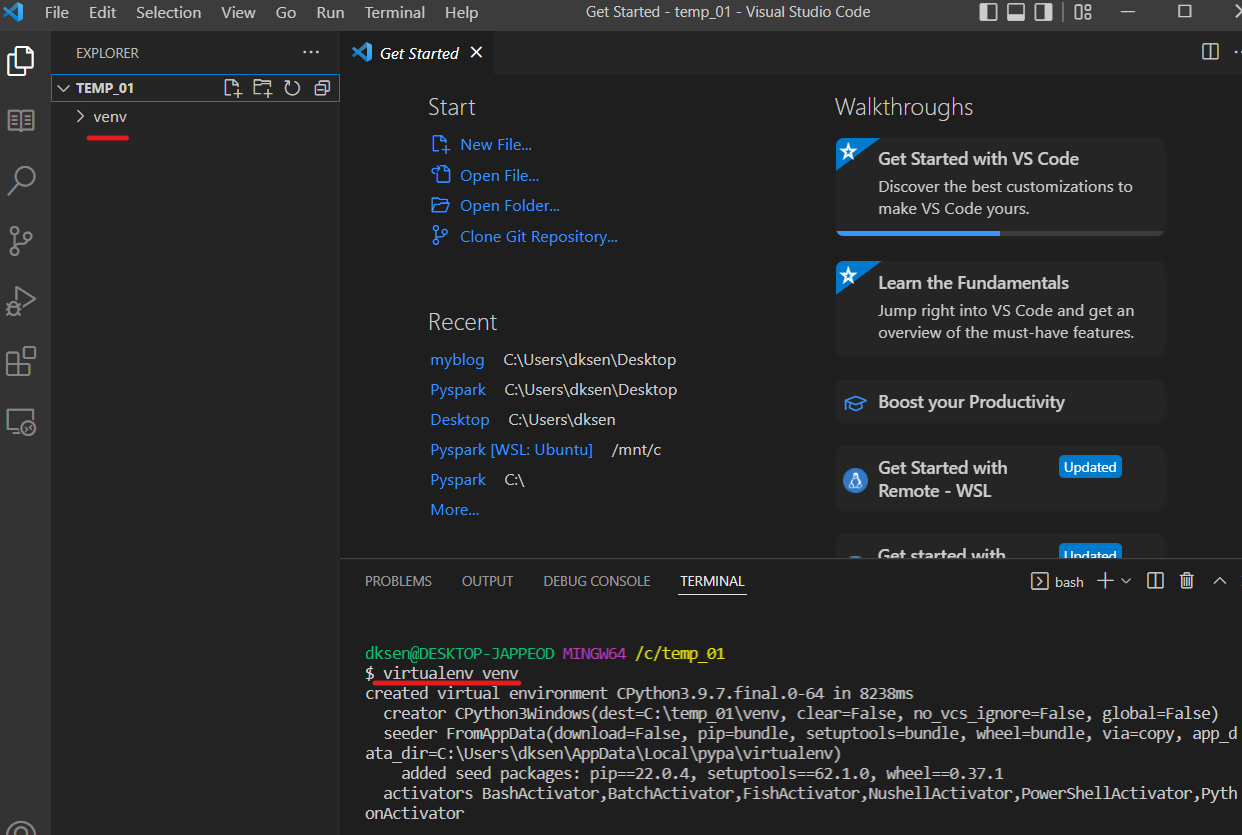
아래 사진에서 필자의 컴퓨터에서 파이썬 라이브러리가 저장된 경로는 두번째 항목이기 때문에 클릭을 하면 설정이 바뀐다.
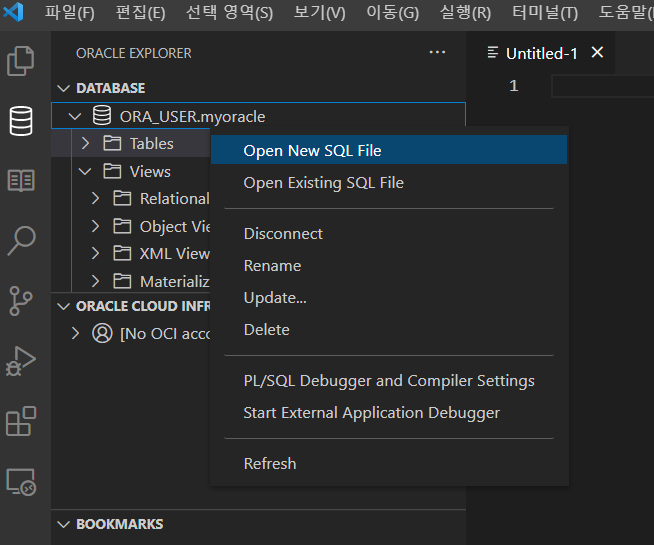
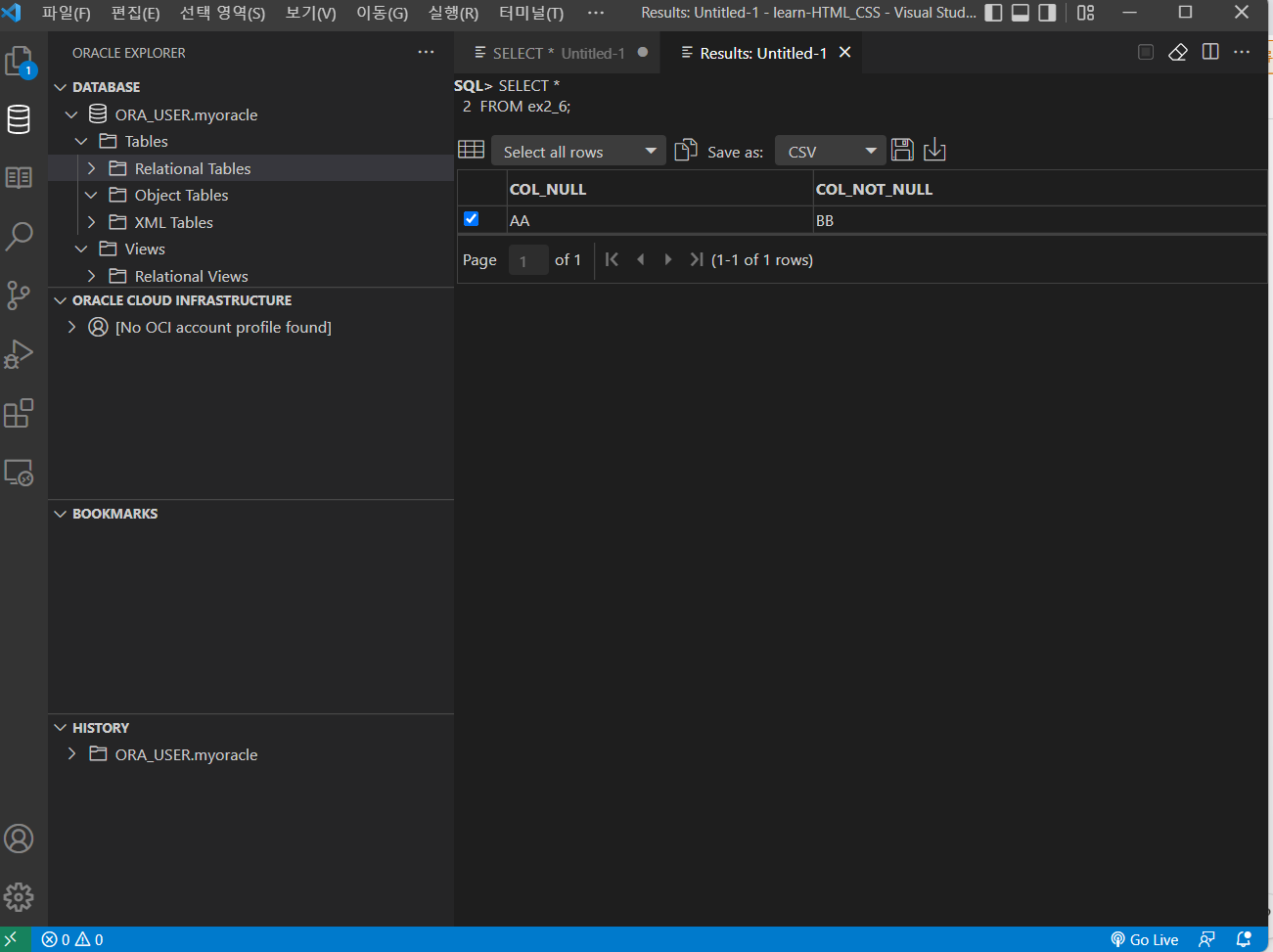
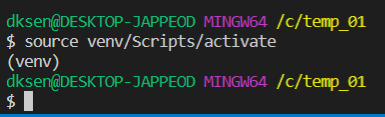
Step 2 방법으로 한번 더 실행하면 아래 사진 과 같이 오류 없이 정상적으로 실행된다.
DB 접속
접속하려는 DB에 맞는 코드를 입력 후 실행
1 2 3 4 5 6 7 8 9 10 11
# SQL Server %sql mssql+pyodbc://user_name:password@host:port_number/db
Python3 가 설치가 되어야 가능하기 때문에 설치가 되어있지 않다면 아나콘다(Anaconda)에 접속하여 설치 바랍니다.
다운로드 전 필수 확인사항
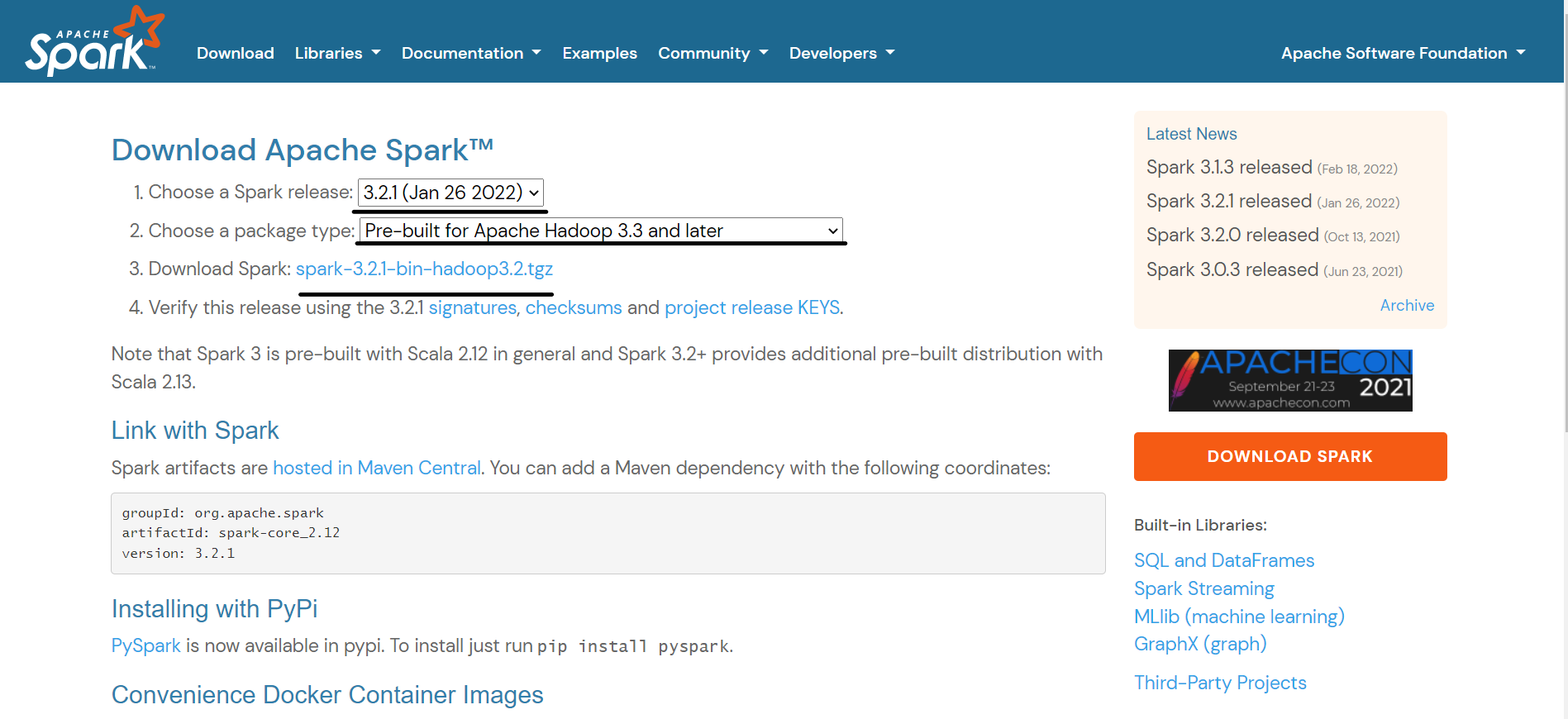
스파크 설치 전에는 반드시 체크해야 하는 사항이 있다. (System Compatibility)
2022년 1월 기준은 아래와 같다.
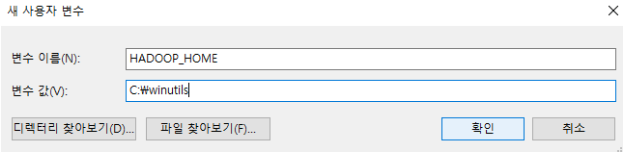
Get Spark from the downloads page of the project website. This documentation is for Spark version 3.2.0. Spark uses Hadoop’s client libraries for HDFS and YARN. Downloads are pre-packaged for a handful of popular Hadoop versions. Users can also download a “Hadoop free” binary and run Spark with any Hadoop version by augmenting Spark’s classpath. Scala and Java users can include Spark in their projects using its Maven coordinates and Python users can install Spark from PyPI.
If you’d like to build Spark from source, visit Building Spark.
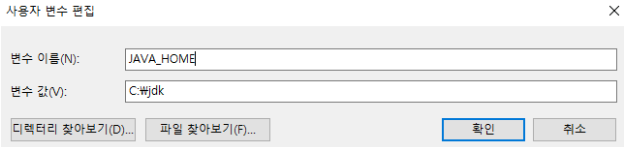
Spark runs on both Windows and UNIX-like systems (e.g. Linux, Mac OS), and it should run on any platform that runs a supported version of Java. This should include JVMs on x86_64 and ARM64. It’s easy to run locally on one machine — all you need is to have java installed on your system PATH, or the JAVA_HOME environment variable pointing to a Java installation.
Spark runs on Java 8/11, Scala 2.12, Python 3.6+ and R 3.5+. Python 3.6 support is deprecated as of Spark 3.2.0. Java 8 prior to version 8u201 support is deprecated as of Spark 3.2.0. For the Scala API, Spark 3.2.0 uses Scala 2.12. You will need to use a compatible Scala version (2.12.x).
For Python 3.9, Arrow optimization and pandas UDFs might not work due to the supported Python versions in Apache Arrow. Please refer to the latest Python Compatibility page. For Java 11, -Dio.netty.tryReflectionSetAccessible=true is required additionally for Apache Arrow library. This prevents java.lang.UnsupportedOperationException: sun.misc.Unsafe or java.nio.DirectByteBuffer.(long, int) not available when Apache Arrow uses Netty internally.
자바 설치
자바를 설치한다. 설치 파일은 아래 링크에서 각자 환경에 맞는 프로그램을 다운로드 받는다.
이 글은 Github blog를 관리 및 운영하는데 필자가 겪은 에러, 어려움 등을 해결하는 과정을 기록할 목적으로 만들어졌습니다.
개요
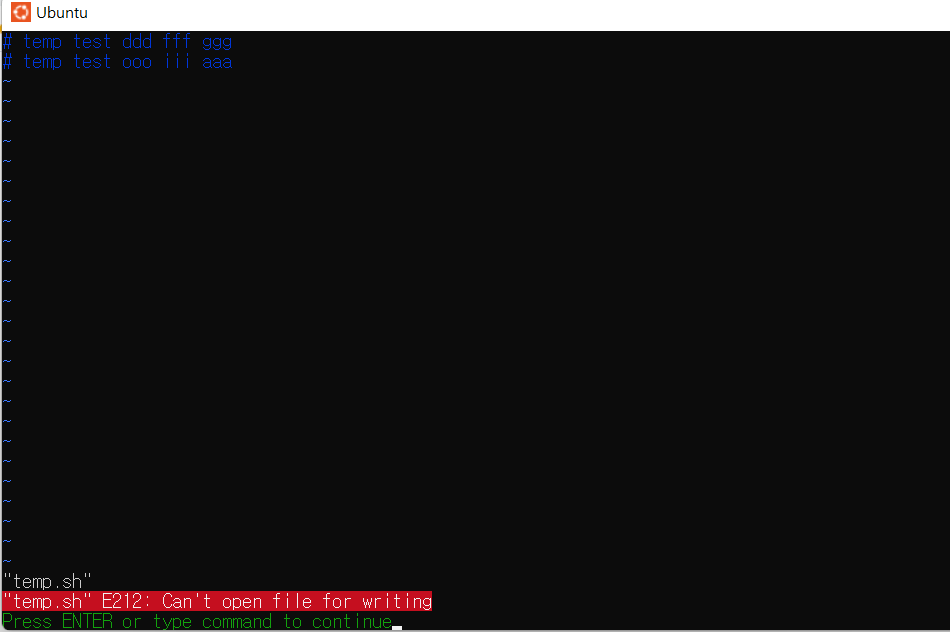
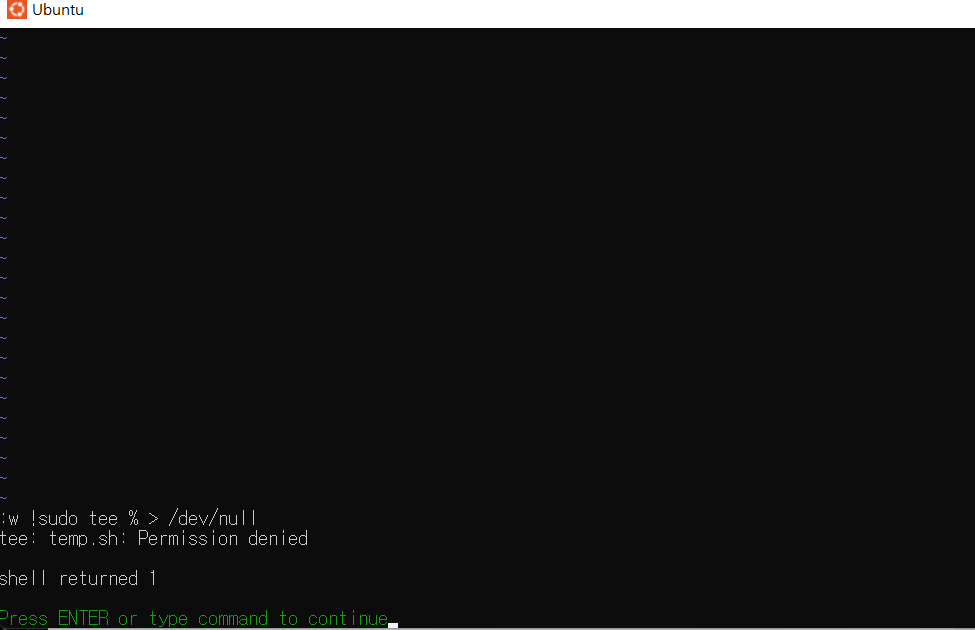
Ubuntu 프로그램 WSL2 Linux 환경에서 발생한 에러인 E212: Can’t open file for writing 를 해결하기 위한 과정을 작성한 것 입니다.(필자는 경로 설정을 잘못하여 에러가 발생한 것이지만 경로 설정이 맞는 일반적인 상황에서의 해결도 작성되어 있습니다.)
22/4/13 강사님의 블로그를 통해 WSL2 설정을 마친 후 Linux 환경에 대한 명령어에 익숙해지기 위해 temp.sh 파일을 생성하여 적응하는 도중 작성한 기록을 저장하는 도중 E212: Can’t open file for writing 에러가 발생하였다. 이 에러는 권한 문제로 나온 것 같다.
이 글은 Github blog를 관리 및 운영하는데 필자가 겪은 에러, 어려움 등을 해결하는 과정을 기록할 목적으로 만들어졌습니다.
평소 Github 블로그에 대해 그 날 들은 강의들만 올리다가 강사님의 따끔하신 일침으로 제대로 된 관리를 해보자 라는 생각이 들어 실행에 옮겨보았다. Github 블로그에 글을 올리는 것은 가능했으나 글을 분류하기 위한 카테고리, 태그 등 깔끔하게 블로그 관리를 못하는 상황이라 블로그를 새롭게 개편해보기로 마음 먹었다.
테마
처음 눈에 뜨인 것은 “블로그 테마” 어떻게 하면 블로그를 조금 더 깔끔하게 보일수 있으면 어떨까란 생각에 다른 사용자의 글을 보며 결국 테마를 “tranquilpeak“ 으로 변경하기로 했다.
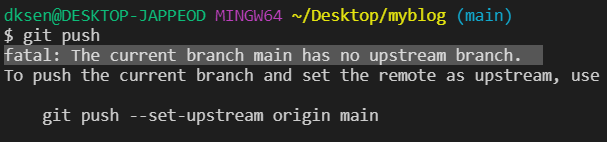
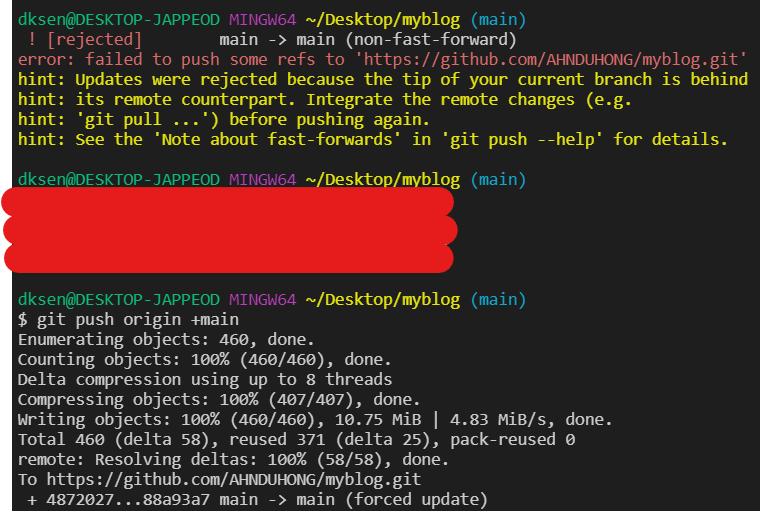
Fatal : refusing to merge unrelated histories : 이 오류는 명령어 git push 또는 git pull을 진행할때 발견할 수 있는 오류, 로컬 저장소와 원격지의 저장소 기록을 비교했을 때 소스코드의 차이가 심한 저장소의 경우, 병합 오류가 날 것을 대비하여 오류 메시지를 띄우는 것 입니다.














_blog_settings_01/1.png)
_blog_settings_01/2.png)
_blog_settings_01/3.png)
_blog_settings_01/4.png)