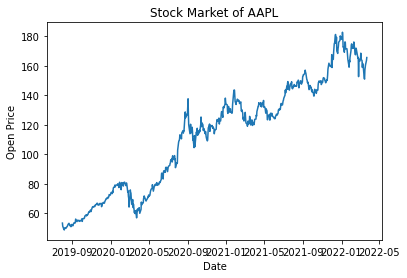
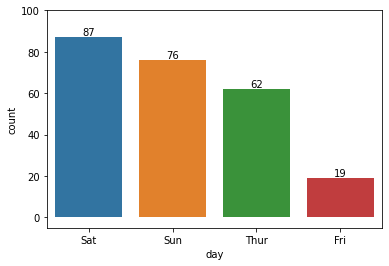import matplotlib.pyplot as plt plt.plot(ts) plt.title("Stock Market of AAPL") # 구글 코랩에서 한글 타이틀은 인식을 못하여 나중에 세팅해야함 plt.xlabel("Date") plt.ylabel("Open Price") plt.show()
1 2 3 4 5 6 7 8
import matplotlib.pyplot as plt
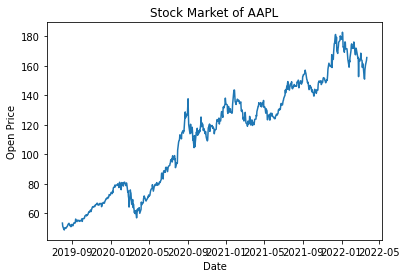
fig, ax = plt.subplots() #fig 는 겉 테두리 ax.plot(ts) ax.set_title("Stock Market of AAPL") ax.set_xlabel("Date") ax.set_ylabel("Open Price") plt.show()
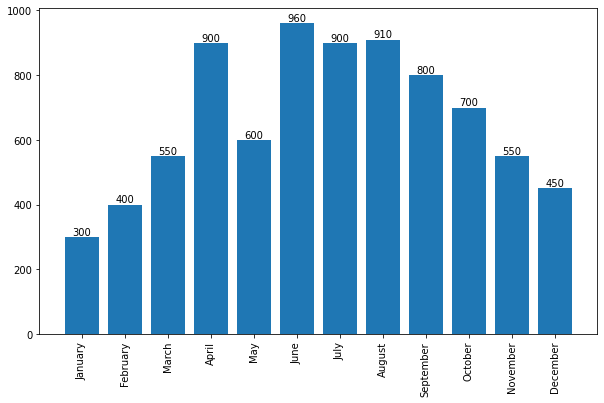
fig, ax = plt.subplots() ax = sns.countplot(x = "day", data = tips, order = tips['day'].value_counts().index)
for plot in ax.patches: # print(plot) height = plot.get_height() ax.text(plot.get_x() + plot.get_width()/2., height, height, ha = 'center', va = 'bottom')
<script>
const buttonEl =
document.querySelector('#df-f18c55cb-276f-414b-b983-0362c3463c87 button.colab-df-convert');
buttonEl.style.display =
google.colab.kernel.accessAllowed ? 'block' : 'none';
async function convertToInteractive(key) {
const element = document.querySelector('#df-f18c55cb-276f-414b-b983-0362c3463c87');
const dataTable =
await google.colab.kernel.invokeFunction('convertToInteractive',
[key], {});
if (!dataTable) return;
const docLinkHtml = 'Like what you see? Visit the ' +
'<a target="_blank" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'
+ ' to learn more about interactive tables.';
element.innerHTML = '';
dataTable['output_type'] = 'display_data';
await google.colab.output.renderOutput(dataTable, element);
const docLink = document.createElement('div');
docLink.innerHTML = docLinkHtml;
element.appendChild(docLink);
}
</script>
</div>
1
juice.loc[juice['Leaflets'] >= 100, 0:2]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-70-46f78a7ec2bf> in <module>()
----> 1 juice.loc[juice['Leaflets'] >= 100, 0:2]
/usr/local/lib/python3.7/dist-packages/pandas/core/indexing.py in __getitem__(self, key)
923 with suppress(KeyError, IndexError):
924 return self.obj._get_value(*key, takeable=self._takeable)
--> 925 return self._getitem_tuple(key)
926 else:
927 # we by definition only have the 0th axis
/usr/local/lib/python3.7/dist-packages/pandas/core/indexing.py in _getitem_tuple(self, tup)
1107 return self._multi_take(tup)
1108
-> 1109 return self._getitem_tuple_same_dim(tup)
1110
1111 def _get_label(self, label, axis: int):
/usr/local/lib/python3.7/dist-packages/pandas/core/indexing.py in _getitem_tuple_same_dim(self, tup)
804 continue
805
--> 806 retval = getattr(retval, self.name)._getitem_axis(key, axis=i)
807 # We should never have retval.ndim < self.ndim, as that should
808 # be handled by the _getitem_lowerdim call above.
/usr/local/lib/python3.7/dist-packages/pandas/core/indexing.py in _getitem_axis(self, key, axis)
1140 if isinstance(key, slice):
1141 self._validate_key(key, axis)
-> 1142 return self._get_slice_axis(key, axis=axis)
1143 elif com.is_bool_indexer(key):
1144 return self._getbool_axis(key, axis=axis)
/usr/local/lib/python3.7/dist-packages/pandas/core/indexing.py in _get_slice_axis(self, slice_obj, axis)
1174
1175 labels = obj._get_axis(axis)
-> 1176 indexer = labels.slice_indexer(slice_obj.start, slice_obj.stop, slice_obj.step)
1177
1178 if isinstance(indexer, slice):
/usr/local/lib/python3.7/dist-packages/pandas/core/indexes/base.py in slice_indexer(self, start, end, step, kind)
5683 slice(1, 3, None)
5684 """
-> 5685 start_slice, end_slice = self.slice_locs(start, end, step=step)
5686
5687 # return a slice
/usr/local/lib/python3.7/dist-packages/pandas/core/indexes/base.py in slice_locs(self, start, end, step, kind)
5885 start_slice = None
5886 if start is not None:
-> 5887 start_slice = self.get_slice_bound(start, "left")
5888 if start_slice is None:
5889 start_slice = 0
/usr/local/lib/python3.7/dist-packages/pandas/core/indexes/base.py in get_slice_bound(self, label, side, kind)
5795 # For datetime indices label may be a string that has to be converted
5796 # to datetime boundary according to its resolution.
-> 5797 label = self._maybe_cast_slice_bound(label, side)
5798
5799 # we need to look up the label
/usr/local/lib/python3.7/dist-packages/pandas/core/indexes/base.py in _maybe_cast_slice_bound(self, label, side, kind)
5747 # reject them, if index does not contain label
5748 if (is_float(label) or is_integer(label)) and label not in self._values:
-> 5749 raise self._invalid_indexer("slice", label)
5750
5751 return label
TypeError: cannot do slice indexing on Index with these indexers [0] of type int
# R install.pakages("패키지명") # 파이썬 라이브러리 설치 코드에서 실행 (x) # 터미널에서 설치 # 방법 1. conda 설치 # --> 아나콘다 설치 후, conda 설치 (데이터 과학) # 방법 2. pip 설치 (개발 + 데이터과학 + 그외) # --> 아나콘다 설치 안함 / 파이썬만 설치
# 5보다 작은 값은 원래값으로 반환 # 5보다 큰 값은 원래 값 * 10 np.where(temp_arr < 5, temp_arr, temp_arr * 10)
array([ 0, 1, 2, 3, 4, 50, 60, 70, 80, 90])
1 2 3 4 5
# 0 - 100 까지의 배열을 만들고, 50보다 작은 값은 곱하기 10, 나머지는 그냥 원래 값으로 반환 # np.where 은 조건식이 하나만 필요할 떄 사용 temp_arr = np.arange(101) # temp_arr np.where(temp_arr < 50, temp_arr * 10, temp_arr)
classPerson: """ 사람을 표현하는 클래스 Attributes ------------ name : str name of the person age : int age of the person Methods ------------- info(additional=""): prints the person's name and age """ def__init__(self, name, age): """ Constructs all the neccessary attributes for the person object Parameters(매개변수) ------------------------- name : str name of the person age : int age of the person """
self.name = name self.age = age
definfo(self, additional = None): """ 귀찮음... Parameters -------------- additional : str, optional more info to be displayed (Default is None) / A, B, C Returens ----------- None """
print(f'My name is {self.name}. I am {self.age} years old. ' + additional)
if __name__ == "__main__": person = Person("Evan", age = 20) person.info("나의 직장은 00이야") help(Person)
My name is Evan. I am 20 years old. 나의 직장은 00이야
Help on class Person in module __main__:
class Person(builtins.object)
| Person(name, age)
|
| 사람을 표현하는 클래스
|
|
|
| Attributes
| ------------
| name : str
| name of the person
|
| age : int
| age of the person
|
| Methods
| -------------
|
| info(additional=""):
| prints the person's name and age
|
| Methods defined here:
|
| __init__(self, name, age)
| Constructs all the neccessary attributes for the person object
|
| Parameters(매개변수)
| -------------------------
| name : str
| name of the person
|
| age : int
| age of the person
|
| info(self, additional=None)
| 귀찮음...
|
| Parameters
| --------------
| additional : str, optional
| more info to be displayed (Default is None) / A, B, C
|
|
| Returens
| -----------
| None
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
# 위 코드의 반복문 코드 작성 필요 절감 for i inrange(len(product_name)): name = product_name[i] sales = prices[i] * quantities[i] print(name + "의 매출액은" + str(sales) + "원이다.")
Help on function temp in module __main__:
temp(content, letter)
content안에 있는 문자를 세는 함수입니다.
Args:
content(str) : 탐색 문자열
letter(str) : 찾을 문자열
Returns:
int
content안에 있는 문자를 세는 함수입니다.
Args:
content(str) : 탐색 문자열
letter(str) : 찾을 문자열
Returns:
int
defmean_and_median(value_list): """ 숫자 리스트 요소들의 평균과 중간값을 구하는 코드를 작성해라 Args: value_list (iterable of int / float): A list of int numbers Return: tuple(float, float) """ # 평균 mean = sum(value_list) / len(value_list) # 중간값 midpoint = int(len(value_list) / 2) iflen(value_list) % 2 == 0: median = (value_list[midpoint - 1] + value_list[midpoint]) / 2 else: median = value_list[midpoint]
a = [] # 빈 리스트 a_func = list() # 빈 리스트 생성 b = [1] # 숫자가 요소가 될 수 있다. c = ['apple'] # 문자열도 요소가 될 수 있다. d = [1, 2, ['apple']] # 리스트 안에 또 다른 리스트를 요소로 넣을 수 있다.